port bootstrap build-ordering tool report 4
Mon, 30 Jul 2012 10:30 categories: blogA copy of this post is sent to soc-coordination@lists.alioth.debian.org as well as to debian-bootstrap@lists.mister-muffin.de.
Diary
July 2
- playing around with syntactic dependency graphs and how to use them to flatten dependencies
July 4
- make work with dose 3.0.2
- add linux-amd64 to source architectures
- remove printing in build_compile_rounds
- catch Not_found exception and print warning
- use the whole installation set in crosseverything.ml instead of flattened dependencies
- detect infinite loop and quit in crosseverything.ml
- use globbing in _tags file
- use wildcards and patsubst in makefile
July 5
- throw a warning if there exist binary packages without source packages
- add string_of_list and string_of_pkglist and adapt print_pkg_list and print_pkg_list_full to use them
- fix and extend flatten_deps - now also tested with Debian Sid
July 6
- do not exclude the crosscompiled packages from being compiled in crosseverything.ml
- clean up basebuildsystem.ml, remove old code, use BootstrapCommon code
- clean up basenocycles.ml, remove unused code and commented out code
- add option to print statistics about the generated dependency graph
- implement most_needed_fast_wrong as well as most_needed_slow_correct and make both available through the menu
July 7
- allow to investigate all scc, not only the full graph and the scc containing the investigated package
- handle Not_found in src_list_from_bin_list with warning message
- handle the event of the whole archive actually being buildable
- replace raise Failure with failwith
- handle incorrectly typed package names
- add first version of reduced_dist.ml to create a self-contained mini distribution out of a big one
July 8
- add script to quickly check for binary packages without source package
- make Debian Sid default in makefile
- add *.d.byte files to .gitignore
- README is helpful now
- more pattern matching and recursiveness everywhere
July 9
- fix termination condition of reduced_dist.ml
- have precise as default ubuntu distribution
- do not allow to investigate an already installable package
July 10
- milestone: show all cycles in a graph
- add copyright info (LGPL3+)
July 11
- advice to use dose tools in README
July 16
- write apt_pkg based python filter script replacing grep-dctrl
July 17
- use Depsolver.listcheck more often
- add dist_graph.ml
- refactor dependency graph code into its own module
July 18
- improve package selection for reduced_dist.ml
- improve performance of cycle enumeration code
July 20
- implement buildprofile support into dose3
July 22
- let dist_graph.ml use commandline arguments
July 23
- allow dose3 to generate source package lists without Build-{Depends|Conflicts}-Indep
July 29
- implement crosscompile support into dose3
Results
Readme
There is not yet a writeup on how everything works and how all the pieces of the code work together but the current README file provides a short introduction on how to use the tools.
- build and runtime dependencies
- compile instructions
- execution examples for each program
- step by step guide how to analyze the dependency situation
- explanation of general commandline options
A detailed writeup about the inner workings of everything will be part of a final documentation stage.
License
All my code is now released under the terms of the LGPL either version 3, or (at your option) any later version. A special linking exception is made to the license which can be read at the top of the provided COPYING file. The exception is necessary because Ocaml links statically, which means that without that exception, the conditions of distribution would basically equal GPL3+.
reduced_dist.ml
Especially the Debian archive is huge and one might want to work on a reduced selection of packages first. Having a smaller selection of the archive would be significantly faster and would also not add thousands of packages that are not important for an extended base system.
I call a reduced distribution a set of source packages A and a set of binary packages B which fulfill the following three properties:
- all source packages A must be buildable with only binary packages B being available
- all binary packages B except for architecture:all packages must be buildable from source packages A
The set of binary packages B and source packages A can be retrieved using the reduced_dist program. It allows to either build the most minimal reduced distribution or one that includes a certain package selection.
To filter out the package control stanzas for a reduced distribution from a full distribution, I originally used a call to grep-dctrl but later replaced that by a custom python script called filter-packages.py. This script uses python-apt to filter Packages and Sources files for a certain package selection.
dist_graph.ml
It soon became obvious that there were not many independent dependency cycle situation but just one big scc that would contain 96% of the packages that are involved in build dependency cycles. Therefor it made sense to write a program that does not iteratively build the dependency graph starting from a single package, but which builds a dependency graph for a whole archive.
Cycles
I can now enumerate all cycles in the dependency graph. I covered the theoretical part in another blog post and wrote an email about the achievement to the list. Both resources contain more links to the respective sourcecode.
The dependency graph generated for Debian Sid has 39486 vertices. It has only one central scc with 1027 vertices and only eight other scc with 2 to 7 vertices. All the other source and binary packages in the dependency graph for the archive are degenerate components of length one.
Obtaining the attached result took 4 hours on my machine (Core i5 @ 2.53GHz). 1.5 h of that were needed to build the dependency graph, the other 2.5 hours were needed to run johnson's algorithm on the result. Memory consumption of the program was at about 700 MB.
It is to my joy that apparently the runtime of the cycle finding algorithm for a whole Debian Sid repository as well as the memory requirements are within orders of magnitude that are justifiable when being run on off-the-shelf hardware. It must also be noted that nothing is optimized for performance yet.
A list of all cycles in Debian Sid up to length 4 can be retrieved from this email. This cycle analysis assumes that only essential packages, build-essential and dependencies and debhelper are available. Debhelper is not an essential or build-essential package but 79% of the archive build-depends on it.
The most interesting cycles are probably those of length 2 that need packages that they build themselves. Noticeable examples for these situations are vala, python, mlton, fpc, sbcl and ghc. Languages seem love to need themselves to be built.
Buildprofiles
There is a long discussion of how to encode staged build dependency information in source packages. While the initial idea was to use Build-Depends-StageN fields, this solution would duplicate large parts of the Build-Depends field, which leads to bitrot as well as it is inflexible to possible other build "profiles". To remedy the situation it was proposed to use field names like Build-Depends[stage1 embedded] but this would also duplicate information and would break with the rfc822 format of package description files. A document maintained by Guillem Jover gives even more ideas and details.
Internally, Patrick and me decided for another idea of Guillem Jover to annotate staged build dependencies. The format reads like:
Build-Depends: huge (>= 1.0) [i386 arm] <!embedded !bootstrap>, tiny
So each build profile would follow a dependency in <> "brackets" an have a similar format as architecture options.
Patrick has a patch for dpkg that implements this functionality while I patched dose3.
Dropping Build-Depends-Indep and Build-Conflicts-Indep
When representing the dependencies of a source package, dose3 concatenates its Build-Depends and Build-Depends-Indep dependency information.
So up to now, a source package could only be compiled, if it manages to compile all of its binary packages including architecture:all packages.
But when bootstrapping a new architecture, it should be sufficient to only build the architecture dependent packages and therefor to only build the build-arch target in debian/rules and not the build-indep target.
Only considering the Build-Depends field and dismissing the Build-Depends-Indep field, reduced the main scc from 1027 vertices to 979 vertices. The amount of cycles up to length four reduced from 276 to 206. Especially the cycles containing gtk-doc-tools, doxygen, debiandoc-sgml and texlive-latex-base got much less.
Patrick managed to add a Build-Depends-Indep field to four packages so far which reduced the scc further by 14 vertices down to 965 vertices.
So besides staged build dependencies and cross building there is now a third method that can be applied to break dependency cycles: add Build-Depends-Indep information to them or update existing information.
I submitted a list of packages that have a binary-indep and/or a build-indep target in their debian/rules to the list.
I also submitted a patch for dose3 to be able to specify to ignore Build-Depends-Indep and Build-Conflicts-Indep information.
Dose3 crossbuilding
So far I only looked at dependency situations in the native case. While the native case contains a huge scc of about 1000 packages, the dependency situation will be much nicer when cross building. But dose3 was so far not able to simulate cross building of source packages. I wrote a patch that implements this functionality and will allow me to write programs that help analyze the cross-situation as well.
Debconf Presentation
Wookey was giving a talk at debconf12 for which I was supplying him with slides. The slides in their final version can be downloaded here
Future
Patrick maintains a list of "weak" build dependencies. Those are dependencies that are very likely to be droppable in either a staged build or using Build-Depends-Indep. I must make use of this list to make it easier to find packages that can easily be removed of their dependencies.
I will have to implement support for resolving the main scc using staged build dependencies. Since it is unlikely that Patrick will be fast enough in supplying me with modified packages, I will need to create myself a database of dummy packages.
Another open task is to allow to analyze the crossbuilding dependency situation.
What I'm currently more or less waiting on is the inclusion of my patches into dose3 as well as a decision on the buildprofile format. More people need to discuss about it until it can be included into tools as well as policy.
Every maintainer of a package can help making bootstrapping easier by making sure that as many dependencies as possible are part of the Build-Depends-Indep field.
enumerating elementary circuits of a directed_graph
Wed, 04 Jul 2012 14:57 categories: codeFor my GSoC project this year I need to be able to enumerate all elementary circuits of a directed graph. My code is written in Ocaml but neither the ocamlgraph library nor graph libraries for other languages seem to implement a well tested algorithm for this task.
In lack of such a well tested solution to the problem, I decided to implement a couple of different algorithms. Since it is unlikely that different algorithms yield the same wrong result, I can be certain enough that each individual algorithm is working correctly in case they all agree on a single solution.
As a result I wrote a testsuite, containing an unholy mixture of Python, Ocaml, D and Java code which implements algorithms by D. B. Johnson, R. Tarjan, K. A. Hawick and H. A. James.
Algorithm by R. Tarjan
The earliest algorithm that I included was published by R. Tarjan in 1973.
Enumeration of the elementary circuits of a directed graph
R. Tarjan, SIAM Journal on Computing, 2 (1973), pp. 211-216
http://dx.doi.org/10.1137/0202017
I implemented the pseudocode given in the paper using Python. The git repository can be found here: https://github.com/josch/cycles_tarjan
Algorithm by D. B. Johnson
The algorithm by D. B. Johnson from 1975 improves on Tarjan's algorithm by its complexity.
Finding all the elementary circuits of a directed graph.
D. B. Johnson, SIAM Journal on Computing 4, no. 1, 77-84, 1975.
http://dx.doi.org/10.1137/0204007
In the worst case, Tarjan's algorithm has a time complexity of O(n⋅e(c+1)) whereas Johnson's algorithm supposedly manages to stay in O((n+e)(c+1)) where n is the number of vertices, e is the number of edges and c is the number of cycles in the graph.
I found two implementations of Johnson's algorithm. One was done by Frank Meyer and can be downloaded as a zip archive. The other was done by Pietro Abate and the code can be found in a blog entry which also points to a git repository.
The implementation by Frank Meyer seemed to work flawlessly. I only had to add code so that a graph could be given via commandline. The git repository of my additions can be found here: https://github.com/josch/cycles_johnson_meyer
Pietro Abate implemented an iterative and a functional version of Johnson's algorithm. It turned out that both yielded incorrect results as some cycles were missing from the output. A fixed version can be found in this git repository: https://github.com/josch/cycles_johnson_abate
Algorithm by K. A. Hawick and H. A. James
The algorithm by K. A. Hawick and H. A. James from 2008 improves further on Johnson's algorithm and does away with its limitations.
Enumerating Circuits and Loops in Graphs with Self-Arcs and Multiple-Arcs.
Hawick and H.A. James, In Proceedings of FCS. 2008, 14-20
www.massey.ac.nz/~kahawick/cstn/013/cstn-013.pdf
In contrast to Johnson's algorithm, the algorithm by K. A. Hawick and H. A. James is able to handle graphs containing edges that start and end at the same vertex as well as multiple edges connecting the same two vertices. I do not need this functionality but add the code as additional verification.
The paper posts extensive code snippets written in the D programming language. A full, working version with all pieces connected together can be found here: https://github.com/josch/cycles_hawick_james
The algorithm was verified using example output given in the paper. The project README states how to reproduce it.
Input format
All four codebases have been modified to produce executables that take the same commandline arguments which describes the graphs to investigate.
The first argument is the number of vertices of the graph. Subsequent arguments are ordered pairs of comma separated vertices that make up the directed edges of the graph.
Lets look at the following graph as an example:
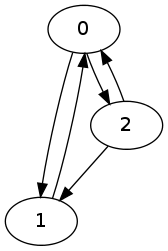
The DOT source for this graph is:
digraph G {
0;
1;
2;
0 -> 1;
0 -> 2;
1 -> 0;
2 -> 0;
2 -> 1;
}
To generate the list of elementary circuits using Tarjan's algorithm for the graph above, use:
$ python cycles.py 3 0,1 0,2 1,0 2,0 2,1
0 1
0 2
0 2 1
The commandline arguments are the exact same for the other three methods and yield the same result in the same order.
If the DOT graph is in a format as simple as above, the following sed construct can be used to generate the commandline argument that represents the graph:
$ echo `sed -n -e '/^\s*[0-9]\+;$/p' graph.dot | wc -l` `sed -n -e 's/^\s*\([0-9]\) -> \([0-9]\);$/\1,\2/p' graph.dot`
Testsuite
As all four codebases take the same input format and have the same output format, it is now trivial to write a testsuite that compares the individual output of each algorithm for the same input and checks for differences.
The code of the testsuite is available via this git repository: https://github.com/josch/cycle_test
The other four repositories exist as submodules of the testsuite repository.
$ git clone git://github.com/josch/cycle_test.git
$ cd cycle_test
$ git submodule update --init
A testrun is done via calling:
$ ./test.sh 11
The argument to the shell script is an integer denoting the maximum number N
of vertices for which graphs will be generated.
The script will compile the Ocaml, Java and D sourcecode of the submodules as
well as an ocaml script called rand_graph.ml which generates random graphs
from v = 1..N vertices where N is given as a commandline argument. For each
number of vertices n, e = 1..M number of edges are chosen where M is
maximum number of edges given the number of vertices. For every combination of
number of vertices v and number of edges e, a graph is randomly generated
using Pack.Digraph.Rand.graph from the ocamlgraph library. Each of those
generated graphs is checked for cycles and written to a file graph-v-e.dot if
the graph contains a cycle.
test.sh then loops over all generated dot files. It uses the above sed
expression to convert each dot file to a commandline argument for each of the
algorithms.
The outputs of each algorithm are then compared with each other and only if they do not differ, does the loop continue. Otherwise the script returns with an exit code.
The tested algorithms are the Python implementation of Tarjan's algorithm, the iterative and functional Ocaml implementation as well as the Java implementation of Johnson's algorithm and the D implementation of the algorithm by Hawick and James.
Future developments
Running the testsuite with a maximum of 12 vertices takes about 33 minutes on a 2.53GHz Core2Duo and produces graphs with as much as 1.1 million cycles. It seems that all five implementations agree on the output for all 504 generated graphs that were used as input.
If there should be another implementation of an algorithm that enumerates all elementary circuits of a directed graph, I would like to add it.
There are some more papers that I would like to read but I lack access to epubs.siam.org and ieeexplore.ieee.org and would have to buy them.
Benchmarks seem a bit pointless as not only the algorithms are very different from each other (and there are many ways to tweak each of them) but also the programming languages differ. Though for the curious kind, it follows the time each algorithm takes to enumerate all cycles for all generated graphs up to 11 vertices.
| algorithm | time (s) |
|---|---|
| Johnson, Abate, Ocaml, iterative | 137 |
| Johnson, Abate, Ocaml, functional | 139 |
| Tarjan, Python | 153 |
| Hawick, D | 175 |
| Johnson, Meyer, Java | 357 |
The iterative Ocaml code performs as well as the functional one. In practice, the iterative code should probably be preferred as the functional code is not tail recursive. On the other hand it is also unlikely that cycles ever grow big enough to make a difference in the used stack space.
The Python implementation executes surprisingly fast, given that Tarjan's algorithm is supposedly inferior to Johnson's and given that Python is interpreted but the Python implementation is also the most simple one with the least amount of required datastructures.
The D code potentially suffers from the bigger datastructures and other bookkeeping that is required to support multi and self arcs.
The java code implements a whole graph library which might explain some of its slowness.
port bootstrap build-ordering tool report 3
Mon, 02 Jul 2012 10:58 categories: blogA copy of this post is sent to soc-coordination@lists.alioth.debian.org as well as to debian-bootstrap@lists.mister-muffin.de.
Diary
June 18
Pietro suggests a faster way to generate installation sets for a list of packages. In my case, I need an installation set for every source package in the archive to find out how often a binary package is needed to build a source package. As a result, the speed is doubled in contrast to the original approach.
June 19
- adapt code to work with new dose release 3.0
- remove unneeded parts of code
- add different possibilities to find amount of source packages that need a binary package
- add code to get multiple installation sets using Depsolver_int.solve
June 20
- add ~global_constraints:false to Depsolver.listcheck, Depsolver.trim and Depsolver.edos_install calls
- adapt output graph to limited xdot capabilities
June 21
I formulate an email to the list, reporting of dependency graphs of debhelper, cdbs, pkg-config and libgtk2.0-dev. My current technique gets an installation set for a source package, removes all those that are already installable and adds the others as a dependency of that source package. This dependency will include an installation set of that binary as well minus all packages that are already available. The problem with that approach are dependency cycles created by long dependency chains. Example: src:A needs B needs C needs A. B and C would both be added as a dependency of src:A. B as well as C would also include their installation set which in both cases includes A. So now there are two cycles: src:A->B->A and src:A->C->A. For a real life example, look at the following situation of cdbs and src:sqlite3.

It is created because src:sqlite3 needs cdbs needs python-scour needs python needs python2.7 needs libsqlite3-0. Therfor libsqlite3-0 is in the installation set of cdbs, python-scour, python and python2.7. This creates five cycles in the graph even though there is only one. It would be better to reduce the dependencies added to src:sqlite3 to its direct dependency which is cdbs.
Package dependencies are disjunctions from which the solver chooses one or the other to build an installation set. To solve the problem above I would need to know which disjunction the solver chose and then only add the direct dependency of a package to the dependency graph.
- improve build_compile_rounds performance
- big overhaul of menu structure
- fix subgraph extraction code
June 22
- do not create a universe if not needed - use hashtables instead
- for sorting packages, generating difference of package sets and otherwise comparing packages, always use CudfAdd.compare
- as a custom list membership function, use List.exists instead of trying List.find
- more speedup for build_compile_rounds
- the number of source packages that can be built does NOT include the cross built packages
- print closure members in graph
- refactor code and move common functions to bootstrapCommon.ml
- add breakcycles.ml for future code to break cycles using staged build dependencies
- use more extlib functionality
- extended package list input format
June 23
After several emails with Pietro I learn about syntactic dependency graphs. To document my progress and prove my efforts I committed the code as commit 6684c13. But this code was soon found out to be unecessary so it will be removed later and just serves as documentation.
June 24
I came up with another (better?) solution to get the chosen disjunctions. It simply uses the calculated installation set to decide for each disjunction which one was taken by the solver. I reported that important step and the open questions involved with it in an email to the list. The problem always was, that an installation set can easily contain more than one package of a disjunction. In this case it is not clear which branch was chosen by the solver. I found, that in Ubuntu Natty there are only 6 such packages and for each of them the situation can be solved. It can be solved because in all of those cases it is that either one package of a disjunction provides the other or that both packages depend upon each other, which means that both have to be included.
June 27
- use installation set to flatten build dependencies of source packages
- refactor code and move common functions to bootstrapCommon.ml
June 25
I have to have an algorithm that finds all circuits in a given graph. This is necessary so that:
- cycles can be enumerated for huge dependency graphs where cycles are hard to see
- cycles can be enumerated to find a cycle that can be broken using staged build dependencies
It seems that Johnson's algorithm is the best way to do this complexity wise and Pietro already blogged about the problem together with an implementation of the algorithm in ocaml. Unfortunately it turns out that his code doesnt implement the algorithm correctly and hence misses out on some cycles. The fix seems not to be too trivial so I'm still investigating it.
June 28
- add crosseverything.ml to obtain a list of source packages that, if cross compiled, would make the whole archive available
Results
While the first week was productive as usual, I had to work some time on a University project during the second week as well as attend a family meeting. I will catch up with the lost time over the course of the next week.
dose3
Using dose 3.0 (which fixes a bug about essential packages) the output of the algorithms is now likely less wrong then before.
performance
Performance was improved in the generation of installation sets as well as in the code that tries out how many packages can be built in multiple rounds. This was achieved by more caching, less unnecessary operations in looping constructs, replacing lists with hashtables, not creating universes where not necessary.
user interface
The main program, basenocycles.ml now has a much better menu structure.
input format
The programs take two package file inputs. The list of source packages that has to be cross built for a minimal build system and the list of source packages that was chosen to be cross compiled in addition to that. Both files list one source package per line and now allow comments.
refactoring
As more and more scripts are added, more and more functionality is moved to bootstrapCommon.ml which makes each script much cleaner.
what to test for cross building
As discussed in the "Future" section of the last report, I now automated the process of finding out which packages, if they were cross compiled, would make the whole archive available because they break all cycles and allow native compilation of the rest. The outcome: to build 3333 out of 3339 packages in natty natively, at most 186 source packages must be cross compiled. The other six cannot be compiled because of version mismatches in the Natty Sources.bz2 and Packages.bz2. The code can be run from crosseverything.ml.
limit source dependencies to direct dependencies
Reducing the dependencies of source packages from their full installation set to their direct dependencies by finding out which disjunction of their dependency list were taken, greatly simplifies the dependency graphs. The dependency graph created for libgtk2.0-dev could be reduced from 491 to 247 vertices for a depth of three.
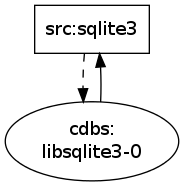
For cdbs it is now clearly visible that cdbs depends on libsqlite3-0 which builds from src:sqlite3 which depends on cdbs.
Before:
After:
For pkg-config the graph also has been reduced to the one single cycle that matters: src:pkg-config needs libglib2.0-dev which depends on pkg-config which builds from src:pkg-config.
Before:
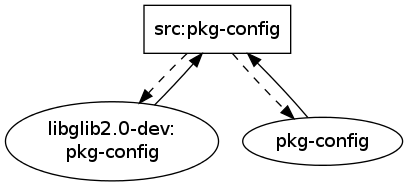
After:
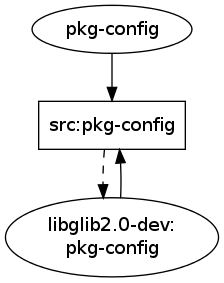
Future
I will prepare content for wookey's debconf talk on crossbuilding and bootstrapping. As this will include directions how to use the current code, I will kill two birds with one stone and write some proper documentation for my current source.
The following two lists will be displayed after a dependency graph is calculated and reduced to its scc:
- those source packages that have the least build dependencies not fulfilled. Those might be candidates for easy staged build dependencies. Since the source package is part of the scc, it will definitely be involved in some cycle somewhere.
- those binary packages that most source packages depend upon. Those could be candidates for cross compilation as it might be easier to cross compile the source package than using staged build dependencies.
Patrick managed to cross build packages with sbuild now. So the list of packages that crosseverything.ml produces can now be checked efficiently for cross buildability. With this list, potentially more cycles can be broken out of the box. A feature will be added that allows the user to remove all packages from a dependency graph that can be cross compiled without any additional effort.
Version mismatches between source and binary packages in Sources.bz2 and Packages.bz2 respectively in Ubuntu make the scripts fail and/or produce wrong results. Debian (even Sid) doesnt have this problem so I should find out where to report this problem to Ubuntu.
I need to write a working version of Johnson's algorithm because much functionality depends upon it. I have the option to improve Pietro's version or write one from scratch. Writing one from scratch might be easier as I have Pietro's code as template as well as a Java implementation of Johnson's algorithm which seems to work.
The following functionalities need working cycle enumeration:
- given source packages with staged build dependencies, an enumeration of cycles is needed to find out which cycles can be broken by building packages staged. It makes less sense to blindly build a package stage and then check if this makes more packages available.
- display cycles of a dependency graph to the user. After obtaining all cycles in the graph it makes sense to sort them by their length. The user would then investigate the situation of the smallest cycles first. This makes sense because breaking small cycles can potentially break bigger cycles. Since in the end, all cycles have to be eliminated anyway, it makes sense for the user to first tackle the small ones.
- display the feedback arc set to the user. The packages in the feedback arc set might be very good candidates for reduced build dependencies or cross compilation.