unshare without superuser privileges
Sun, 25 Oct 2015 18:44 categories: code, debian, linuxTLDR: With the help of Helmut Grohne I finally figured out most of the bits
necessary to unshare everything without becoming root (though one might say
that this is still cheated because the suid root tools newuidmap and newgidmap
are used). I wrote a Perl script which documents how this is done in practice.
This script is nearly equivalent to using the existing commands lxc-usernsexec
[opts] -- unshare [opts] -- COMMAND except that these two together cannot be
used to mount a new proc. Apart from this problem, this Perl script might also
be useful by itself because it is architecture independent and easily
inspectable for the curious mind without resorting to sources.debian.net (it is
heavily documented at nearly 2 lines of comments per line of code on average).
It can be retrieved here at
https://gitlab.mister-muffin.de/josch/user-unshare/blob/master/user-unshare
Long story: Nearly two years after my last last rant about everything needing
superuser privileges in
Linux,
I'm still interested in techniques that let me do more things without becoming
root. Helmut Grohne had told me for a while about unshare(), or user namespaces
as the right way to have things like chroot without root. There are also
reports of LXC containers working without root privileges but they are hard to
come by. A couple of days ago I had some time again, so Helmut helped me to get
through the major blockers that were so far stopping me from using unshare in a
meaningful way without executing everything with sudo.
My main motivation at that point was to let dpkg-buildpackage when executed
by sbuild be run with an unshared network namespace and thus without network
access (except for the loopback interface) because like pbuilder I wanted
sbuild to enforce the rule not to access any remote resources during the build.
After several evenings of investigating and doctoring at the Perl script I
mentioned initially, I came to the conclusion that the only place that can
unshare the network namespace without disrupting anything is schroot itself.
This is because unsharing inside the chroot will fail because
dpkg-buildpackage is run with non-root privileges and thus the user namespace
has to be unshared. But this then will destroy all ownership information. But
even if that wasn't the case, the chroot itself is unlikely to have (and also
should not) tools like ip or newuidmap and newgidmap installed. Unsharing
the schroot call itself also will not work. Again we first need to unshare the
user namespace and then schroot will complain about wrong ownership of its
configuration file /etc/schroot/schroot.conf. Luckily, when contacting Roger
Leigh about this wishlist feature in
bug#802849 I was told that this was already
implemented in its git master \o/. So this particular problem seems to be taken
care of and once the next schroot release happens, sbuild will make use of it
and have unshare --net capabilities just like pbuilder already had since
last year.
With the sbuild case taken care of, the rest of this post will introduce the
Perl script I wrote.
The name user-unshare is really arbitrary. I just needed some identifier for
the git repository and a filename.
The most important discovery I made was, that Debian disables unprivileged user
namespaces by default with the patch
add-sysctl-to-disallow-unprivileged-CLONE_NEWUSER-by-default.patch to the
Linux kernel. To enable it, one has to first either do
echo 1 | sudo tee /proc/sys/kernel/unprivileged_userns_clone > /dev/null
or
sudo sysctl -w kernel.unprivileged_userns_clone=1
The tool tries to be like unshare(1) but with the power of lxc-usernsexec(1) to
map more than one id into the new user namespace by using the programs
newgidmap and newuidmap. Or in other words: This tool tries to be like
lxc-usernsexec(1) but with the power of unshare(1) to unshare more than just
the user and mount namespaces. It is nearly equal to calling:
lxc-usernsexec [opts] -- unshare [opts] -- COMMAND
Its main reason of existence are:
- as a project for me to learn how unprivileged namespaces work
- written in Perl which means:
- architecture independent (same executable on any architecture)
- easily inspectable by other curious minds
- tons of code comments to let others understand how things work
- no need to install the lxc package in a minimal environment (perl itself might not be called minimal either but is present in every Debian installation)
- not suffering from being unable to mount proc
I hoped that systemd-nspawn could do what I wanted but it seems that its
requirement for being run as root will not change any time
soon
Another tool in Debian that offers to do chroot without superuser privileges is
linux-user-chroot but that one cheats by being suid root.
Had I found lxc-usernsexec earlier I would've probably not written this. But
after I found it I happily used it to get an even better understanding of the
matter and further improve the comments in my code. I started writing my own
tool in Perl because that's the language sbuild was written in and as mentioned
initially, I intended to use this script with sbuild. Now that the sbuild
problem is taken care of, this is not so important anymore but I like if I can
read the code of simple programs I run directly from /usr/bin without having to
retrieve the source code first or use sources.debian.net.
The only thing I wasn't able to figure out is how to properly mount proc into
my new mount namespace. I found a workaround that works by first mounting a new
proc to /proc and then bind-mounting /proc to whatever new location for
proc is requested. I didn't figure out how to do this without mounting to
/proc first partly also because this doesn't work at all when using
lxc-usernsexec and unshare together. In this respect, this perl script is a
bit more powerful than those two tools together. I suppose that the reason is
that unshare wasn't written with having being called without superuser
privileges in mind. If you have an idea what could be wrong, the code has a big
FIXME about this issue.
Finally, here a demonstration of what my script can do. Because of the /proc
bug, lxc-usernsexec and unshare together are not able to do this but it
might also be that I'm just not using these tools in the right way. The
following will give you an interactive shell in an environment created from one
of my sbuild chroot tarballs:
$ mkdir -p /tmp/buildroot/proc
$ ./user-unshare --mount-proc=/tmp/buildroot/proc --ipc --pid --net \
--uts --mount --fork -- sh -c 'ip link set lo up && ip addr && \
hostname hoothoot-chroot && \
tar -C /tmp/buildroot -xf /srv/chroot/unstable-amd64.tar.gz; \
/usr/sbin/chroot /tmp/buildroot /sbin/runuser -s /bin/bash - josch && \
umount /tmp/buildroot/proc && rm -rf /tmp/buildroot'
(unstable-amd64-sbuild)josch@hoothoot-chroot:/$ whoami
josch
(unstable-amd64-sbuild)josch@hoothoot-chroot:/$ hostname
hoothoot-chroot
(unstable-amd64-sbuild)josch@hoothoot-chroot:/$ ls -lha /proc | head
total 0
dr-xr-xr-x 218 nobody nogroup 0 Oct 25 19:06 .
drwxr-xr-x 22 root root 440 Oct 1 08:42 ..
dr-xr-xr-x 9 root root 0 Oct 25 19:06 1
dr-xr-xr-x 9 josch josch 0 Oct 25 19:06 15
dr-xr-xr-x 9 josch josch 0 Oct 25 19:06 16
dr-xr-xr-x 9 root root 0 Oct 25 19:06 7
dr-xr-xr-x 9 josch josch 0 Oct 25 19:06 8
dr-xr-xr-x 4 nobody nogroup 0 Oct 25 19:06 acpi
dr-xr-xr-x 6 nobody nogroup 0 Oct 25 19:06 asound
Of course instead of running this long command we can also instead write a small shell script and execute that instead. The following does the same things as the long command above but adds some comments for further explanation:
#!/bin/sh
set -exu
# I'm using /tmp because I have it mounted as a tmpfs
rootdir="/tmp/buildroot"
# bring the loopback interface up
ip link set lo up
# show that the loopback interface is really up
ip addr
# make use of the UTS namespace being unshared
hostname hoothoot-chroot
# extract the chroot tarball. This must be done inside the user namespace for
# the file permissions to be correct.
#
# tar will fail to call mknod and to change the permissions of /proc but we are
# ignoring that
tar -C "$rootdir" -xf /srv/chroot/unstable-amd64.tar.gz || true
# run chroot and inside, immediately drop permissions to the user "josch" and
# start an interactive shell
/usr/sbin/chroot "$rootdir" /sbin/runuser -s /bin/bash - josch
# unmount /proc and remove the temporary directory
umount "$rootdir/proc"
rm -rf "$rootdir"
and then:
$ mkdir -p /tmp/buildroot/proc
$ ./user-unshare --mount-proc=/tmp/buildroot/proc --ipc --pid --net --uts --mount --fork -- ./chroot.sh
As mentioned in the beginning, the tool is nearly equivalent to calling
lxc-usernsexec [opts] -- unshare [opts] -- COMMAND but because of the problem
with mounting proc (mentioned earlier), lxc-usernsexec and unshare cannot
be used with above example. If one tries anyways one will only get:
$ lxc-usernsexec -m b:0:1000:1 -m b:1:558752:1 -- unshare --mount-proc=/tmp/buildroot/proc --ipc --pid --net --uts --mount --fork -- ./chroot.sh
unshare: mount /tmp/buildroot/proc failed: Invalid argument
I'd be interested in finding out why that is and how to fix it.
Reliable IMAP synchronization with IDLE support
Wed, 05 Jun 2013 06:47 categories: codeThe task: reliably synchronize my local MailDir with several remote IMAP mailboxes with IDLE support so that there is no need to poll with small time intervals to get new email immediately.
Most graphical mail clients like icedove/thunderbird or evolution have IDLE support which means that their users get notified about new email as soon as it arrives. I prefer to handle email fetching/reading/sending using separate programs so after having used icedove for a long time, I switched to a offlineimap/mutt based setup a few years ago. Some while after that I discovered sup and later notmuch/alot which made me switch again. Now my only remaining problem is the synchronization between my local email and several remote IMAP servers.
Using offlineimap worked fine in the beginning but soon I discovered some of its shortcomings. It would for example sometimes lock up or simply crash when I switched between different wireless networks or switched to ethernet or UMTS. Crashing was not a big problem as I just put it into a script which re-executed it every time it crashed. The problem was it locking up for one of its synchronizing email accounts while the others were kept in sync as usual. This once let to me missing five days of email because offlineimap was not crashing and I believed everything was fine (new messages from the other accounts were scrolling by as usual) while people were sending me worried emails whether I was okay or if something bad had happened. I nearly missed a paper submission deadline and another administrative deadline due to this. This was insanely annoying. It turned out that other mail synchronization programs suffered from the same lockup problem so I stuck with offlineimap and instead executed it as:
while true; do
timeout --signal=KILL 1m offlineimap
notmuch new
sleep 5m
done
Which would synchronize my email every five minutes and kill offlineimap if a synchronization took more than one minute. While I would've liked an email synchronizer which would not need this measure, this worked fine over the months.
After some while it bugged me that icedove (which my girlfriend is using) was
receiving email nearly instantaneously after they arrived and I couldnt have
this feature with my setup. This instantaneous arrival of email works by using
the IMAP IDLE command which allows the server to notify the client once new
email arrives instead of the client having to poll for new email in small
intervals. Unfortunately offlineimap (and any other email synchronizer I
found) would not support the IDLE command. There is a fork of it which supports
IDLE by using a newer python imap library but this is of little use to me as
there is no possibility of a hook which executes when new email arrives so that
I can execute notmuch new on the new email. At this point I could've used
inotify to execute notmuch new upon arrival of new email but I went another
way.
Here is a short python script idle.py which connects to my IMAP servers and
sends the IDLE command:
import imaplib
import select
import sys
class mysock():
def __init__(self, name, server, user, passwd, directory):
self.name = name
self.directory = directory
self.M = imaplib.IMAP4(server)
self.M.login(user, passwd)
self.M.select(self.directory)
self.M.send("%s IDLE\r\n"%(self.M._new_tag()))
if not self.M.readline().startswith('+'): # expect continuation response
exit(1)
def fileno(self):
return self.M.socket().fileno()
if __name__ == '__main__':
sockets = [
mysock("Name1", "imap.foo.bar", "user1", "pass1", "folder1"),
mysock("Name1", "imap.foo.bar", "user1", "pass1", "folder2"),
mysock("Name2", "imap.blub.bla", "user2", "pass2", "folder3")
]
readable, _, _ = select.select(sockets, [], [], 1980) # 33 mins timeout
found = False
for sock in readable:
if sock.M.readline().startswith('* BYE '): continue
print "-u basic -o -q -f %s -a %s"%(sock.directory, sock.name)
found = True
break
if not found:
print "-u basic -o"
It would create a connection to every directory I want to watch on every email account I want to synchronize. The select call will expire after 33 minutes as most email servers would drop the connection if nothing happens at around 30 minutes. If something happened within that time though, the script would output the arguments to offlineimap to do a quick check on just that mailbox on that account. If nothing happened, the script would output the arguments to offlineimap to do a full check on all my mailboxes.
while true; do
args=`timeout --signal=KILL 35m python idle.py` || {
echo "idle timed out" >&2;
args="-u basic -o";
}
echo "call offlineimap with: $args" >&2
timeout --signal=KILL 1m offlineimap $args || {
echo "offlineimap timed out" >&2;
continue;
}
notmuch new
done
Every call which interacts with the network is wrapped in a timeout command
to avoid any funny effects. Should the python script timeout, a full
synchronization with offlineimap is triggered. Should offlineimap timeout, an
error message is written to stderr and the script continues. The above
naturally has the disadvantage of not immediately responding to new email which
arrives during the time that idle.py is not running. But as this email will
be fetched once the next message arrives on the same account, there is no much
waiting time and so far, this problem didnt bite me.
Is there a better way to synchronize my email and at a same time make use of IDLE? I'm surprised I didnt find software which would offer this feature.
enumerating elementary circuits of a directed_graph
Wed, 04 Jul 2012 14:57 categories: codeFor my GSoC project this year I need to be able to enumerate all elementary circuits of a directed graph. My code is written in Ocaml but neither the ocamlgraph library nor graph libraries for other languages seem to implement a well tested algorithm for this task.
In lack of such a well tested solution to the problem, I decided to implement a couple of different algorithms. Since it is unlikely that different algorithms yield the same wrong result, I can be certain enough that each individual algorithm is working correctly in case they all agree on a single solution.
As a result I wrote a testsuite, containing an unholy mixture of Python, Ocaml, D and Java code which implements algorithms by D. B. Johnson, R. Tarjan, K. A. Hawick and H. A. James.
Algorithm by R. Tarjan
The earliest algorithm that I included was published by R. Tarjan in 1973.
Enumeration of the elementary circuits of a directed graph
R. Tarjan, SIAM Journal on Computing, 2 (1973), pp. 211-216
http://dx.doi.org/10.1137/0202017
I implemented the pseudocode given in the paper using Python. The git repository can be found here: https://github.com/josch/cycles_tarjan
Algorithm by D. B. Johnson
The algorithm by D. B. Johnson from 1975 improves on Tarjan's algorithm by its complexity.
Finding all the elementary circuits of a directed graph.
D. B. Johnson, SIAM Journal on Computing 4, no. 1, 77-84, 1975.
http://dx.doi.org/10.1137/0204007
In the worst case, Tarjan's algorithm has a time complexity of O(n⋅e(c+1)) whereas Johnson's algorithm supposedly manages to stay in O((n+e)(c+1)) where n is the number of vertices, e is the number of edges and c is the number of cycles in the graph.
I found two implementations of Johnson's algorithm. One was done by Frank Meyer and can be downloaded as a zip archive. The other was done by Pietro Abate and the code can be found in a blog entry which also points to a git repository.
The implementation by Frank Meyer seemed to work flawlessly. I only had to add code so that a graph could be given via commandline. The git repository of my additions can be found here: https://github.com/josch/cycles_johnson_meyer
Pietro Abate implemented an iterative and a functional version of Johnson's algorithm. It turned out that both yielded incorrect results as some cycles were missing from the output. A fixed version can be found in this git repository: https://github.com/josch/cycles_johnson_abate
Algorithm by K. A. Hawick and H. A. James
The algorithm by K. A. Hawick and H. A. James from 2008 improves further on Johnson's algorithm and does away with its limitations.
Enumerating Circuits and Loops in Graphs with Self-Arcs and Multiple-Arcs.
Hawick and H.A. James, In Proceedings of FCS. 2008, 14-20
www.massey.ac.nz/~kahawick/cstn/013/cstn-013.pdf
In contrast to Johnson's algorithm, the algorithm by K. A. Hawick and H. A. James is able to handle graphs containing edges that start and end at the same vertex as well as multiple edges connecting the same two vertices. I do not need this functionality but add the code as additional verification.
The paper posts extensive code snippets written in the D programming language. A full, working version with all pieces connected together can be found here: https://github.com/josch/cycles_hawick_james
The algorithm was verified using example output given in the paper. The project README states how to reproduce it.
Input format
All four codebases have been modified to produce executables that take the same commandline arguments which describes the graphs to investigate.
The first argument is the number of vertices of the graph. Subsequent arguments are ordered pairs of comma separated vertices that make up the directed edges of the graph.
Lets look at the following graph as an example:
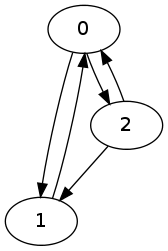
The DOT source for this graph is:
digraph G {
0;
1;
2;
0 -> 1;
0 -> 2;
1 -> 0;
2 -> 0;
2 -> 1;
}
To generate the list of elementary circuits using Tarjan's algorithm for the graph above, use:
$ python cycles.py 3 0,1 0,2 1,0 2,0 2,1
0 1
0 2
0 2 1
The commandline arguments are the exact same for the other three methods and yield the same result in the same order.
If the DOT graph is in a format as simple as above, the following sed construct can be used to generate the commandline argument that represents the graph:
$ echo `sed -n -e '/^\s*[0-9]\+;$/p' graph.dot | wc -l` `sed -n -e 's/^\s*\([0-9]\) -> \([0-9]\);$/\1,\2/p' graph.dot`
Testsuite
As all four codebases take the same input format and have the same output format, it is now trivial to write a testsuite that compares the individual output of each algorithm for the same input and checks for differences.
The code of the testsuite is available via this git repository: https://github.com/josch/cycle_test
The other four repositories exist as submodules of the testsuite repository.
$ git clone git://github.com/josch/cycle_test.git
$ cd cycle_test
$ git submodule update --init
A testrun is done via calling:
$ ./test.sh 11
The argument to the shell script is an integer denoting the maximum number N
of vertices for which graphs will be generated.
The script will compile the Ocaml, Java and D sourcecode of the submodules as
well as an ocaml script called rand_graph.ml which generates random graphs
from v = 1..N vertices where N is given as a commandline argument. For each
number of vertices n, e = 1..M number of edges are chosen where M is
maximum number of edges given the number of vertices. For every combination of
number of vertices v and number of edges e, a graph is randomly generated
using Pack.Digraph.Rand.graph from the ocamlgraph library. Each of those
generated graphs is checked for cycles and written to a file graph-v-e.dot if
the graph contains a cycle.
test.sh then loops over all generated dot files. It uses the above sed
expression to convert each dot file to a commandline argument for each of the
algorithms.
The outputs of each algorithm are then compared with each other and only if they do not differ, does the loop continue. Otherwise the script returns with an exit code.
The tested algorithms are the Python implementation of Tarjan's algorithm, the iterative and functional Ocaml implementation as well as the Java implementation of Johnson's algorithm and the D implementation of the algorithm by Hawick and James.
Future developments
Running the testsuite with a maximum of 12 vertices takes about 33 minutes on a 2.53GHz Core2Duo and produces graphs with as much as 1.1 million cycles. It seems that all five implementations agree on the output for all 504 generated graphs that were used as input.
If there should be another implementation of an algorithm that enumerates all elementary circuits of a directed graph, I would like to add it.
There are some more papers that I would like to read but I lack access to epubs.siam.org and ieeexplore.ieee.org and would have to buy them.
Benchmarks seem a bit pointless as not only the algorithms are very different from each other (and there are many ways to tweak each of them) but also the programming languages differ. Though for the curious kind, it follows the time each algorithm takes to enumerate all cycles for all generated graphs up to 11 vertices.
| algorithm | time (s) |
|---|---|
| Johnson, Abate, Ocaml, iterative | 137 |
| Johnson, Abate, Ocaml, functional | 139 |
| Tarjan, Python | 153 |
| Hawick, D | 175 |
| Johnson, Meyer, Java | 357 |
The iterative Ocaml code performs as well as the functional one. In practice, the iterative code should probably be preferred as the functional code is not tail recursive. On the other hand it is also unlikely that cycles ever grow big enough to make a difference in the used stack space.
The Python implementation executes surprisingly fast, given that Tarjan's algorithm is supposedly inferior to Johnson's and given that Python is interpreted but the Python implementation is also the most simple one with the least amount of required datastructures.
The D code potentially suffers from the bigger datastructures and other bookkeeping that is required to support multi and self arcs.
The java code implements a whole graph library which might explain some of its slowness.
network file transfer to marvell kirkwood
Sat, 19 May 2012 01:06 categories: codeI have a Seagate GoFlex Net with two 2TB harddrives attached to it via SATA. The device itself is connected to my PC via its Gigabit Ethernet connection. It houses a Marvell Kirkwood at 1.2GHz and 128MB. I am booting Debian from a USB stick connected to its USB 2.0 port.
The specs are pretty neat so I planned it as my NAS with 4TB of storage being attached to it. The most common use case is the transfer of big files (1-10 GB) between my laptop and the device.
Now what are the common ways to achieve this?
scp:
scp /local/path user@goflex:/remote/path
rsync:
rsync -Ph /local/path user@goflex:/remote/path
sshfs:
sshfs -o user@goflex:/remote/path /mnt
cp /local/path /mnt
ssh:
ssh user@goflex "cat > /remote/path" < /local/path
I then did some benchmarks to see how they perform:
scp: 5.90 MB/s
rsync: 5.16 MB/s
sshfs: 5.05 MB/s
ssh: 5.42 MB/s
Since they all use ssh for transmission, the similarity of the result does not come as a surprise and 5.90 MB/s are also not too shabby for a plain scp. It means that I can transfer 1 GB in a bit under three minutes. I could live with that. Even for 10 GB files I would only have to wait for half an hour which is mostly okay since it is mostly known well in advance that a file is needed.
As adam points out in the comments, I can also use try using another cipher than AES for ssh. So I tried to use arcfour and blowfish-cbc.
scp+arcfour: 12.4MB/s
scp+blowfish: 9.0MB/s
But lets see if we can somehow get faster than this. Lets analyze where the bottleneck is.
Lets have a look at the effective TCP transfer rate with netcat:
ssh user@goflex "netcat -l -p 8000 > /dev/null"
dd if=/dev/zero bs=10M count=1000 | netcat goflex 8000
79.3 MB/s wow! Can we get more? Lets try increasing the buffer size on both ends. This can be done using nc6 with the -x argument on both sides.
ssh user@goflex "netcat -x -l -p 8000 > /dev/null"
dd if=/dev/zero bs=10M count=1000 | netcat -x gloflex 8000
103 MB/s okay this is definitely NOT the bottleneck here.
Lets see how fast I can read from my harddrive:
hdparm -tT /dev/sda
114.86 MB/s.. hmm... and writing to it?
ssh user@goflex "time sh -c 'dd if=/dev/zero of=/remote/path bs=10M count=100; sync'"
42.93 MB/s
Those values are far faster than my puny 5.90 MB/s I get with scp. A look at the CPU usage during transfer shows, that the ssh process is at 100% CPU usage the whole time. It seems the bottleneck was found to be ssh and the encryption/decryption involved.
I'm transferring directly from my laptop to the device. Not even a switch is in the middle so encryption seems to be quite pointless here. Even authentication doesnt seem to be necessary in this setup. So how to make the transfer unencrypted?
The ssh protocol specifies a null cipher for not-encrypted connections. OpenSSH doesnt support this. Supposedly, adding
{ "none", SSH_CIPHER_NONE, 8, 0, 0, EVP_enc_null }
to cipher.c adds a null cipher but I didnt want to patch around in my installation.
So lets see how a plain netcat performs.
ssh user@goflex "netcat -l -p 8000 > /remote/path"
netcat goflex 8000 < /local/path
32.9 MB/s This is far better! Lets try a bigger buffer:
ssh user@goflex "netcat -x -l -p 8000 > /remote/path"
netcat -x goflex 8000 < /local/path
37.8 MB/s now this is far better! My Gigabyte will now take under half a minute and my 10 GB file under five minutes.
But it is tedious to copy multiple files or even a whole directory structure with netcat. There are far better tools for this.
An obvious candidate that doesnt encrypt is rsync when being used with the rsync protocol.
rsync -Ph /local/path user@goflex::module/remote/path
30.96 MB/s which is already much better!
I used the following line to have the rsync daemon being started by inetd:
rsync stream tcp nowait root /usr/bin/rsync rsyncd --daemon
But it is slower than pure netcat.
If we want directory trees, then how about netcatting a tarball?
ssh user@goflex "netcat -x -l -p 8000 | tar -C /remote/path -x"
tar -c /local/path | netcat goflex 8000
26.2 MB/s so tar seems to add quite the overhead.
How about ftp then? For this test I installed vsftpd and achieved a speed of 30.13 MB/s. This compares well with rsync.
I also tried out nfs. Not surprisingly, its transfer rate is up in par with rsync and ftp at 31.5 MB/s.
So what did I learn? Lets make a table:
| method | speed in MB/s |
|---|---|
| scp | 5.90 |
| rsync+ssh | 5.16 |
| sshfs | 5.05 |
| ssh | 5.42 |
| scp+arcfour | 12.4 |
| scp+blowfish | 9.0 |
| netcat | 32.9 |
| netcat -x | 37.8 |
| netcat -x | tar | 26.2 |
| rsync | 30.96 |
| ftp | 30.13 |
| nfs | 31.5 |
For transfer of a directory structure or many small files, unencrypted rsync seems the way to go. It outperforms a copy over ssh more than five-fold.
When the convenience of having the remote data mounted locally is needed, nfs outperforms sshfs at speeds similar to rsync and ftp.
As rsync and nfs already provide good performance, I didnt look into a more convenient solution using ftp.
My policy will now be to use rsync for partial file transfers and mount my remote files with nfs.
For transfer of one huge file, netcat is faster. Especially with increased buffer sizes it is a quarter faster than without.
But copying a file with netcat is tedious and hence I wrote a script that simplifies the whole remote-login, listen, send process to one command. First argument is the local file, second argument is the remote name and path just as in scp.
#!/bin/sh -e
HOST=${2%%:*}
USER=${HOST%%@*}
if [ "$HOST" = "$2" -o "$USER" = "$HOST" ]; then
echo "second argument is not of form user@host:path" >&2
exit 1
fi
HOST=${HOST#*@}
LPATH=$1
LNAME=`basename "$1"`
RPATH=`printf %q ${2#*:}/$LNAME`
ssh "$USER@$HOST" "nc6 -x -l -p 8000 > $RPATH" &
sleep 1.5
pv "$LPATH" | nc6 -x "$HOST" 8000
wait $!
ssh "$USER@$HOST" "md5sum $RPATH" &
md5sum "$LPATH"
wait $!
I use pv to get a status of the transfer on my local machine and ssh to login
to the remote machine and start netcat in listening mode. After the transfer I
check the md5sum to be sure that everything went fine. This step can of course
be left out but during testing it was useful. Escaping of the arguments is done
with printf %q.
Problems with the above are the sleep, which can not be avoided but must be there to give the remote some time to start netcat and listen. This is unclean. A next problem with the above is, that one has to specify a username. Another is, that in scp, one has to double-escape the argument while above this is not necessary. The host that it netcats to is the same as the host it ssh's to. This is not necessarily the case as one can specify an alias in ~/.ssh/config. Last but not least this only transfers from the local machine to the remote host. Doing it the other way round is of course possible in the same manner but then one must be able to tell how the local machine is reachable for the remote host.
Due to all those inconveniences I decided not to expand on the above script.
Plus, rsync and nfs seem to perform well enough for day to day use.
a periodic counter
Fri, 18 May 2012 20:36 categories: codetldr: counting without cumulative timing errors
Sometimes I want just a small counter, incrementing an integer each second running somewhere in a terminal. Maybe it is because my wristwatch is in the bathroom or because I want to do more rewarding things than counting seconds manually. Maybe I want not only to know how long something takes but also for how long it already ran in the middle of its execution? There are many reason why I would want some script that does nothing else than simply counting upward or downward with some specific frequency.
Some bonuses:
- the period should be possible to give as a floating point number and especially periods of a fraction of a second would be nice
- it should be able to execute an arbitrary program after each period
- it should not matter how long the execution of this program takes for the overall counting
Now this can not be hard, right? One would probably write this line and be done with it:
while sleep 1; do echo $i; i=$((i+1)); done
or to count for a certain number of steps:
for i in `seq 1 100`; do echo $i; sleep 1; done
This would roughly do the job but in each iteration some small offset would be added and though small, this offset would quickly accumulate.
Sure that cumulative error is tiny but given that this task seems to be so damn trivial I couldn't bear anymore with running any of the above but started looking into a solution.
Sure I could just quickly hack a small C script that would check gettimeofday(2) at each iteration and would adjust the time to usleep(3) accordinly but there HAD to be people before me with the same problem who already came up with a solution.
And there was! The solution is the sleepenh(1) program which, when given the timestamp of its last invocation and the sleep time in floating point seconds, will sleep for just the right amount to keep the overall frequency stable.
The author suggests, that sleepenh is to be used in shell scripts that need to repeat an action in a regular time interval and that is just what I did.
The result is trivial and simple but does just what I want:
- the interval will stay the same on average and the counter will not "fall behind"
- count upward or downward
- specify interval length as a floating point number of seconds including fractions of one second
- begin to count at given integer and count for a specific number of times or until infinity
- execute a program at every step, optionally by forking it from the script for programs possibly running longer than the given interval
You can check it out and read how to use and what to do with it on github:
https://github.com/josch/periodic
Now lets compare the periodic script with the second example from above:
$ time sh -c 'for i in `seq 1 1000`; do echo $i; sleep 1; done'
0.08s user 0.12s system 0% cpu 16:41.55 total
So after only 1000 iterations, the counter is already off by 1.55 seconds. This means that instead of having run with a frequency of 1.0 Hz, the actual frequency was 1.00155 Hz. Is it too much to not want this 0.155% of error?
$ time ./periodic -c 1000
0.32s user 0.00s system 0% cpu 16:40.00 total
1000 iterations took exactly 1000 seconds. Cool.