mapbender - maps for long-distance travels
Thu, 03 Apr 2014 11:20 categories: openstreetmapBack in 2007 I stumbled over the "Plus Fours Routefinder", an invention of the 1920's. It's worn on the wrist and allows the user to scroll through a map of the route they planned to take, rolled up on little wooden rollers.

At that point I thought: that's awesome for long trips where you either dont want to take electronics with you or where you are without any electricity for a long time. And creating such rollable custom maps of your route automatically using openstreetmap data should be a breeze! Nevertheless it seems nobody picked up the idea.
Years passed and in a few weeks I'll go on a biking trip along the Weser, a river in nothern Germany. For my last multi-day trip (which was through the Odenwald, an area in southern Germany) I printed a big map from openstreetmap data which contained the whole route. Openstreetmap data is fantastic for this because in contrast to commercial maps it doesnt only allow you to just print the area you need but also allows you to highlight your planned route and objects you would probably not find in most commercial maps like for example supermarkets to stock up on supplies or bicycle repair shops.
Unfortunately such big maps have the disadvantage that to show everything in the amount of detail that you want along your route, they have to be pretty huge and thus easily become an inconvenience because the local plotter can't handle paper as large as DIN A0 or because it's a pain to repeatedly fold and unfold the whole thing every time you want to look at it. Strong winds are also no fun with a huge sheet of paper in your hands. One solution would be to print DIN A4 sized map regions in the desired scale. But that has the disadvantage that either you find yourself going back and forth between subsequent pages because you happen to be right at the border between two pages or you have to print sufficiently large overlaps, resulting in many duplicate map pieces and more pages of paper than you would like to carry with you.
It was then that I remembered the "Plus Fours Routefinder" concept. Given a predefined route it only shows what's important to you: all things close to the route you plan to travel along. Since it's a long continuous roll of paper there is no problem with folding because as you travel along the route you unroll one end and roll up the other. And because it's a long continuous map there is also no need for flipping pages or large overlap regions. There is not even the problem of not finding a big enough sheet of paper because multiple DIN A4 sheets can easily be glued together at their ends to form a long roll.

On the left you see the route we want to take: the bicycle route along the Weser river. If I wanted to print that map on a scale that allows me to see objects in sufficient detail along our route, then I would also see objects in Hamburg (upper right corner) in the same amount of detail. Clearly a waste of ink and paper as the route is never even close to Hamburg.

As the first step, a smooth approximation of the route has to be found. It seems that the best way to do that is to calculate a B-Spline curve approximating the input data with a given smoothness. On the right you can see the approximated curve with a smoothing value of 6. The curve is sampled into 20 linear segments. I calculated the B-Spline using the FITPACK library to which scipy offers a Python binding.
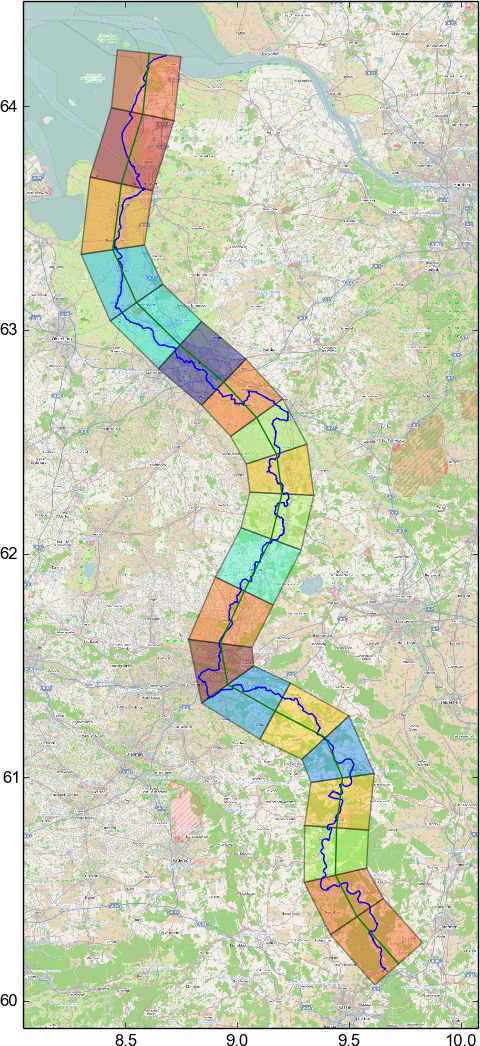
The next step is to expand each of the line segments into quadrilaterals. The distance between the vertices of the quadrilaterals and the ends of the line segment they belong to is the same along the whole path and obviously has to be big enough such that every point along the route falls into one quadrilateral. In this example, I draw only 20 quadrilaterals for visual clarity. In practice one wants many more for a smoother approximation.


Using a simple transform, each point of the original map and the original path in each quadrilateral is then mapped to a point inside the corresponding "straight" rectangle. Each target rectangle has the height of the line segment it corresponds to. It can be seen that while the large scale curvature of the path is lost in the result, fine details remain perfectly visible. The assumption here is, that while travelling a path several hundred kilometers long, it does not matter that large scale curvature that one is not able to perceive anyways is not preserved.
The transformation is done on a Mercator projection of the map itself as well as the data of the path. Therefore, this method probably doesnt work if you plan to travel to one of the poles.
Currently I transform openstreetmap bitmap data. This is not quite optimal as it leads to text on the map being distorted. It would be just as easy to apply the necessary transformations to raw openstreetmap XML data but unfortunately I didnt find a way to render the resulting transformed map data as a raster image without setting up a database. I would've thought that it would be possible to have a standalone program reading openstreetmap XML and dumping out raster or svg images without a round trip through a database. Furthermore, tilemill, one of the programs that seem to be one of the least hasslesome to set up and produce raster images is stuck in an ITP and the existing packaging attempt fails to produce a non-empty binary package. Since I have no clue about nodejs packaging, I wrote about this to the pkg-javascript-devel list. Maybe I can find a kind soul to help me with it.
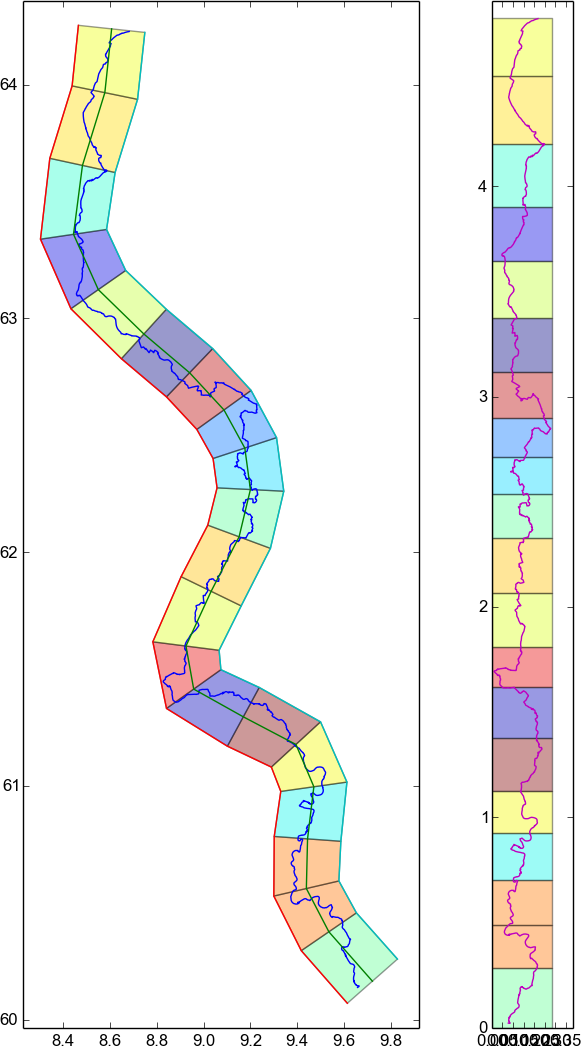
Here a side by side overview that doesnt include the underlying map data but only the path. It shows how small details are preserved in the transformation.
The code that produced the images in this post is very crude, unoptimized and kinda messy. If you dont care, then it can be accessed here
botch updates
Thu, 06 Feb 2014 14:20 categories: debianMy last update about ongoing development of botch, the bootstrap/build ordering tool chain, was three months ago with the announcement of bootstrap.debian.net. Since then a number of things happened, so I thought an update was due.
New graphs for port metrics
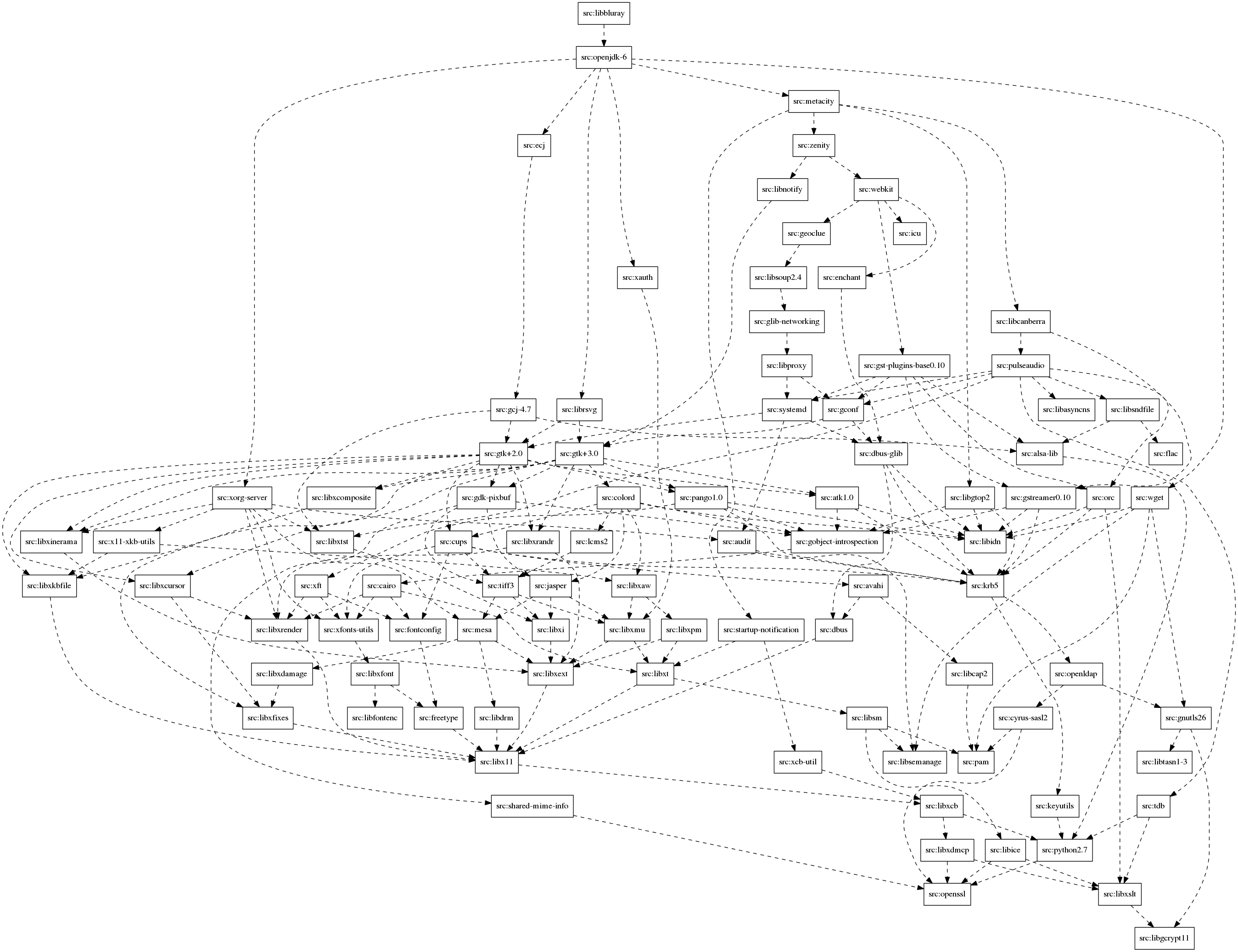
By default, a dependency graph is created by arbitrarily choosing an installation set for binary package installation or source package compilation. Installation set vertices and source vertices are connected according to this arbitrary selection.
Niels Thykier approached me at Debconf13 about the possibility of using this graph to create a metric which would be able to tell for each source package, how many other source packages would become uncompilable or how many binary packages would become uninstallable, if that source package was removed from the archive. This could help deciding about the importance of packages. More about this can be found at the thread on debian-devel.
For botch, this meant that two new graph graphs can now be generated. Instead of picking an arbitrary installation set for compiling a source package or installing a binary package, botch can now create a minimum graph which is created by letting dose3 calculate strong dependencies and a maximum graph by using the dependency closure.
Build profile syntax in dpkg
With dpkg 1.17.2 we now have experimental build profile support in unstable. The syntax which ended up being added was:
Build-Depends: large (>= 1.0), small <!profile.stage1>
But until packages with that syntax can hit the archive, a few more tools need to understand the syntax. The patch we have for sbuild is very simple because sbuild relies on libdpkg for dependency parsing.
We have a patch for apt too, but we have to rebase it for the current apt version and have to adapt it so that it works exactly like the functionality dpkg implements. But before we can do that we have to decide how to handle mixed positive and negative qualifiers or whether to remove this feature altogether because it causes too much confusion. The relevant thread on debian-dpkg starts here.
Update to latest dose3 git
Botch heavily depends on libdose3 and unfortunately requires features which are only available in the current git HEAD. The latest version packaged in Debian is 3.1.3 from October 2012. Unfortunately the current dose3 git HEAD also relies on unreleased features from libcudf. On top of that, the GraphML output of the latest ocamlgraph version (1.8.3) is also broken and only fixed in the git. For now everything is set up as git submodules but this is the major blocker preventing any packaging of botch as a Debian package. Hopefully new releases will be done soon for all involved components.
Writing and reading GraphML
Botch is a collection of several utilities which are connected together in a shell script. The advantage of this is, that one does not need to understand or hack the OCaml code to use botch for different purposes. In theory it also allows to insert 3rd party tools into a pipe to further modify the data. Until recently this ability was seriously hampered by the fact that many botch tools communicated with each other through marshaled OCaml binary files which prevent everything which is not written in OCaml from modifying them. The data that was passed around like this were the dependency graphs and I initially implemented it like that because I didnt want to write a GraphML parser.
I now ended up writing an xmlm based GraphML parser so as of now, botch
only reads and writes ASCII text files in XML (for the graphs) and in rfc822
packages format (for Packages and Sources files) which can both easily be
modified by 3rd party tools. The ./tools directory contains many Python
scripts using the networkx module to modify GraphML and the apt_pkg module to
modify rfc822 files.
Splitting of tools
To further increase the ability to modify program execution without having to know OCaml, I split up some big tools into multiple smaller ones. Some of the smaller tools are now even written in Python which is probably much more hackable for the general crowd. I converted those tools to Python which did not need any dose3 functionality and which were simple enough so that writing them didnt take much time. I could convert more tools but that might introduce bugs and takes time which I currently dont have much of (who does?).
Gzip instead of bz2
Since around January 14, snapshot.debian.org doesnt offer bzip2 compressed Packages and Sources files anymore but uses xz instead. This is awesome for must purposes but unfortunately I had to discover that there exist no OCaml bindings for libxz. Thus, botch is now using gzip instead of bz2 until either myself or anybody else finds some time to write a libxz OCaml binding.
Self hosting Fedora
Paul Wise made me aware of Harald Hoyer's attempts to bootstrap Fedora. I reproduced his steps for the Debian dependency graph and it turns out that they are a little bit bigger. I'm exchanging emails with Harald Hoyer because it might not be too hard to use botch for rpm based distributions as well because dose3 supports rpm.
{kind=link}
{kind=link}
{kind=link}
The article also made me aware of the tred tool which is part of graphviz and
allows to calculate the transitive reduction of a graph. This can help
making horrible situations much better.
{kind=link}
{kind=link}
Dose3 bugs
I planned to generate such simplified graphs for the neighborhood of each source package on bootstrap.debian.net but then binutils stopped building binutils-gold and instead provided binutils-gold while libc6-dev breaks binutils-gold (<< 2.20.1-11). This unfortunately triggered a dose3 bug and thus bootstrap.debian.net will not generate any new results until this is fixed in dose3.
Another dose3 bug affects packages which Conflicts/Replaces/Provides:bar while bar is fully virtual and are Multi-Arch:same. Binaries of different architecture with this property can currently not be co-installed with dose3. Unfortunately linux-libc-dev has this property and thus botch cannot be used to analyze cross builds until that bug is fixed in dose3.
I hope I get some free time soon to be able to look at these dose3 issues myself.
More documentation
Since I started to like the current set of tools and how they work together I ended up writing over 2600 words of documentation in the past few days.
You can start setting up and running botch by reading the first steps and get more detailed information by reading about the 28 tools that botch makes use of as of now.
All existing articles, thesis and talks are linked from the wiki home.
Why do I need superuser privileges when I just want to write to a regular file
Sat, 11 Jan 2014 01:21 categories: debian, linuxI have written a number of scripts to create Debian foreign architecture (mostly armel and armhf) rootfs images for SD cards or NAND flashing. I started with putting Debian on my Openmoko gta01 and gta02 and continued with devices like the qi nanonote, a marvel kirkwood based device, the Always Innovating Touchbook (close to the Beagleboard), the Notion Ink Adam and most recently the Golden Delicious gta04. Once it has been manufactured, I will surely also get my hands dirty with the Neo900 whose creators are currently looking for potential donors/customers to increase the size of the first batch and get the price per unit further down.
Creating a Debian rootfs disk image for all these devices basically follows the same steps:
- create an disk image file, partition it, format the partitions and mount the
/partition into a directory - use
debootstrapormultistrapto extract a selection of armel or armhf packages into the directory - copy over
/usr/bin/qemu-arm-staticfor qemu user mode emulation - chroot into the directory to execute package maintainer scripts with
dpkg --configure -a - copy the disk image onto the sd card
It was not long until I started wondering why I had to run all of the above steps with superuser privileges even though everything except the final step (which I will not cover here) was in principle nothing else than writing some magic bytes to files I had write access to (the disk image file) in some more or less fancy ways.
So I tried using fakeroot+fakechroot and after some initial troubles I
managed to build a foreign architecture rootfs without needing root
priviliges for steps two, three and four. I wrote about my solution which
still included some workarounds in another article here. These
workarounds were soon not needed anymore as upstream fixed the outstanding
issues. As a result I wrote the polystrap tool which combines
multistrap, fakeroot, fakechroot and qemu user mode emulation. Recently
I managed to integrate proot support in a separate branch of
polystrap.
Last year I got the LEGO ev3 robot for christmas and since it runs Linux I also
wanted to put Debian on it by following the instructions given by the ev3dev
project. Even though ev3dev calls itself a "distribution" it only deviates
from pure Debian by its kernel, some configuration options and its initial
package selection. Otherwise it's vanilla Debian. The project also supplies
some multistrap based scripts which create the rootfs and then
partition and populate an SD card. All of this is of course done as the
superuser.
While the creation of the file/directory structure of the foreign Debian armel
rootfs can by now easily be done without superuser priviliges by running
multistrap under fakeroot/fakechroot/proot, creating the SD card image
still seems to be a bit more tricky. While it is no problem to write a
partition table to a regular file, it turned out to be tricky to mount these
partition because tools like kpartx and losetup require superuser
permissions. Tools like mkfs.ext3 and fuse-ext2 which otherwise would be
able to work on a regular file without superuser privileges do not seem to
allow to specify the required offsets that the partitions have within the disk
image. With fuseloop there exists a tool which allows to "loop-mount"
parts of a file in userspace to a new file and thus allows tools like
mkfs.ext3 and fuse-ext2 to work as they normally do. But fuseloop is not
packaged for Debian yet and thus also not in the current Debian stable. An
obvious workaround would be to create and fill each partition in a separate
file and concatenate them together. But why do I have to write my data twice
just because I do not want to become the superuser? Even worse: because
parted refuses to write a partition table to a file which is too small to
hold the specified partitions, one spends twice the disk space of the final
image: the image with the partition table plus the image with the main
partition's content.
So lets summarize: a bootable foreign architecture SD card disk image is nothing else than a regular file representing the contents of the SD card as a block device. This disk image is created in my home directory and given enough free disk space there is nothing stopping me from writing any possible permutation of bits to that file. Obviously I'm interested in a permutation representing a valid partition table and file systems with sensible content. Why do I need superuser privileges to generate such a sensible permutation of bits?
Gladly it seems that the (at least in my opinion) hardest part of faking chroot
and executing foreign architecture package maintainer scripts is already
possible without superuser privileges by using fakeroot and fakechroot or
proot together with qemu user mode emulation. But then there is still the
blocker of creating the disk image itself through some user mode loop mounting
of a filesystem occupying a virtual "partition" in the disk image.
Why has all this only become available so very recently and still requires a
number of workarounds to fully work in userspace? There exists a surprising
amount of scripts which wrap debootstrap/multistrap. Most of them require
superuser privileges. Does everybody just accept that they have to put a sudo
in front of every invocation and hope for the best? While this might be okay
for well tested code like debootstrap and multistrap the countless wrapper
scripts might accidentally (be it a bug in the code or a typo in the given
command line arguments) write to your primary hard disk instead of your SD
card. Such behavior can easily be mitigated by not executing any such script
with superuser privileges in the first place.
Operations like loop mounting affect the whole system. Why do I have to touch
anything outside of my home directory (/dev/loop in this case) to populate a
file in it with some meaningful bits? Virtualization is no option because every
virtualization solution again requires root privileges.
One might argue that a number of solutions just require some initial setup by
root to then later be used by a regular user (for example /etc/fstab
configuration or the schroot approach). But then again: why do I have to
write anything outside of my home directory (even if it is only once) to be
able to write something meaningful to a file in it?
The latter approach also does not work if one cannot become root in the first place or is limited by a virtualized environment. Imagine you are trying to build a Debian rootfs on a machine where you just have a regular user account. Or a situation I was recently in: I had a virtual server which denied me operations like loop mounting.
Given all these downsides, why is it still so common to just assume that one is
able and willing to use sudo and be done with it in most cases?
I really wonder why technologies like fakeroot and fakechroot have only
been developed this late. Has this problem not been around since the earliest
days of Linux/Unix?
Am I missing something and rambling around for nothing? Is this idea a lost cause or something that is worth spending time and energy on to extend and fix the required tools?
announcing bootstrap.debian.net
Tue, 05 Nov 2013 09:20 categories: debianThe following post is a verbatim copy of my message to the debian-devel list.
While botch produces loads of valuable data to help maintainers modifying the right source packages with build profiles and thus make Debian bootstrappable, it has so far failed at producing this data in a format which is:
- human readable (nobody wants to manually go through 12 MB of JSON data)
- generated automatically periodically and published somewhere (nobody wants to run botch on his own machine or update periodically update the TODO wiki page)
- available on a per-source-package-basis (no maintainer wants to know about the 500 source packages he does NOT maintain)
While human readability is probably still lacking (it's hard to write in a manner understandable by everybody about a complicated topic you are very familiar with), the bootstrapping results are now generated automatically (on a daily basis) and published in a per-source-package-basis as well. Thus let me introduce to you:
Paul Wise encouraged me to set this up and also donated the debian.net CNAME to my server. Thanks a lot! The data is generated daily from the midnight packages/sources records of snapshot.debian.org (I hope it's okay to grab the data from there on a daily basis). The resulting data can be viewed in HTML format (with some javascript for to allow table sorting and paging in case you use javascript) per architecture (here for amd64). In addition it also produces HTML pages per source package for all source packages which are involved in a dependency cycle in any architecture (for example src:avahi or src:python2.7). Currently there are 518 source packages involved in a dependency cycle. While this number seems high, remember that estimations by calculating a feedback arc set suggest that only 50-60 of these source packages have to be modified with build profiles to make the whole graph acyclic.
For now it is funny to see that the main architectures do not bootstrap (since July, for different reasons) while less popular ones like ia64 and s390x bootstrap right now without problems (at least in theory). According to the logs (also accessible at above link, here for amd64) this is because gcc-4.6 currently fails compiling due to a build-conflict (this has been reported in bug#724865). Once this bug is fixed, all arches should be bootstrappable again. Let me remind you here that the whole analysis is done on the dependency relationships only (not a single source package is actually compiled at any point) and compilation might fail for many other reasons in practice.
It has been the idea of Paul Wise to integrate this data into the pts so that maintainers of affected source packages can react to the heuristics suggested by botch. For this purpose, the website also publishes the raw JSON data from which the HTML pages are generated (here for amd64). The bugreport against the bts can be found in bug#728298.
I'm sure that a couple of things regarding understandability of the results are not yet sufficiently explained or outright missing. If you see any such instance, please drop me a mail, suggesting what to change in the textual description or presentation of the results.
I also created the following two wiki pages to give an overview of the utilized terminology:
Feel also free to tell me if anything in these pages is unclear.
Direct patches against the python code producing the HTML from the raw JSON data are also always welcome.
Using botch to generate transition build orders
Thu, 11 Jul 2013 16:25 categories: debianIn October 2012, Joachim Breitner asked me whether botch (well, it
didnt have a name back then) can also be used to calculate a build order for
recompiling ~450 haskell-packages with a new ghc version (it was probably
the 7.6.1 release) to upload them to experimental. What is still blocking this
ability is the inability of botch to directly read *.dsc files instead of
having to rely on Packages and Sources files. On the other hand (in case
there exists a set of Packages and Sources files) it is now much easier to
use botch for such a use case for which it was not originally designed.
To demonstrate how botch can be used to calculate the build order for library
transitions, I wrote the script create-transition-order.sh which
executes the individual botch tools in the correct order with the correct
arguments. To validate the correctness of botch, I compared its output to the
order which ben produces for the same transitions.
The create-transition-order.sh script is called with a ben query string and
optionally a snapshot.debian.org timestamp as its arguments. The script
relies on ben being installed because ben query strings cannot be translated
into grep-dctrl query strings as ben query splits fields which contain
comma separated values (like Depends and Build-Depends) at the comma before
it searches for matching strings. Unfortunately, the
create-transition-order.sh script also currently relies on a yet unreleased
ben feature which allows ben download to create a ben.cache file. You can
track the progress of this feature as bug#714703. Creating a ben.cache
file is necessary because some queries rely on an association between binary
and source packages which is not present in all packages in a Packages file.
For example the haskell transition query makes use of this feature by
including the .source field in its query.
The result of these trials was, that botch produced nearly the same build order for nearly all transitions. The only differences are due to shortcomings of ben and botch.
For example, ben is not able to create an order for transitions where involved
packages form one or more cycles. A prominent example is the haskell
transition where ghc itself is only built during step 15 after many other
packages which would have needed ghc to be compiled first. Botch solves this
problem by reducing all strongly connected components in a cyclic graph to a
single vertex before creating the order. This operation makes the graph acyclic
and creating a build order trivially. The only remaining problems can then be
found within the strongly connected components (for Haskell they are of maximum
size two) but the overall build order is correct.
On the other hand botch has no notion of packages which are affected by a transition and thus creates a build order which in some cases is longer than the one created by ben. When generating the interdependencies between packages, ben only considers those which are part of the transition. Botch on the other hand considers all dependency relationships. It would be simple to solve this issue in botch by removing unaffected packages from the dependency graph through edge contraction (an operation already used by botch for other tasks).
This exercise also let me find another bug in dose3 where libdose would
not associate a binary package with a binNMU version with its associated source
package but instead report a version mismatch error. This problem was also
reported in the dose bug tracker.