Reliable IMAP synchronization with IDLE support
Wed, 05 Jun 2013 06:47 categories: codeThe task: reliably synchronize my local MailDir with several remote IMAP mailboxes with IDLE support so that there is no need to poll with small time intervals to get new email immediately.
Most graphical mail clients like icedove/thunderbird or evolution have IDLE support which means that their users get notified about new email as soon as it arrives. I prefer to handle email fetching/reading/sending using separate programs so after having used icedove for a long time, I switched to a offlineimap/mutt based setup a few years ago. Some while after that I discovered sup and later notmuch/alot which made me switch again. Now my only remaining problem is the synchronization between my local email and several remote IMAP servers.
Using offlineimap worked fine in the beginning but soon I discovered some of its shortcomings. It would for example sometimes lock up or simply crash when I switched between different wireless networks or switched to ethernet or UMTS. Crashing was not a big problem as I just put it into a script which re-executed it every time it crashed. The problem was it locking up for one of its synchronizing email accounts while the others were kept in sync as usual. This once let to me missing five days of email because offlineimap was not crashing and I believed everything was fine (new messages from the other accounts were scrolling by as usual) while people were sending me worried emails whether I was okay or if something bad had happened. I nearly missed a paper submission deadline and another administrative deadline due to this. This was insanely annoying. It turned out that other mail synchronization programs suffered from the same lockup problem so I stuck with offlineimap and instead executed it as:
while true; do
timeout --signal=KILL 1m offlineimap
notmuch new
sleep 5m
done
Which would synchronize my email every five minutes and kill offlineimap if a synchronization took more than one minute. While I would've liked an email synchronizer which would not need this measure, this worked fine over the months.
After some while it bugged me that icedove (which my girlfriend is using) was
receiving email nearly instantaneously after they arrived and I couldnt have
this feature with my setup. This instantaneous arrival of email works by using
the IMAP IDLE command which allows the server to notify the client once new
email arrives instead of the client having to poll for new email in small
intervals. Unfortunately offlineimap (and any other email synchronizer I
found) would not support the IDLE command. There is a fork of it which supports
IDLE by using a newer python imap library but this is of little use to me as
there is no possibility of a hook which executes when new email arrives so that
I can execute notmuch new on the new email. At this point I could've used
inotify to execute notmuch new upon arrival of new email but I went another
way.
Here is a short python script idle.py which connects to my IMAP servers and
sends the IDLE command:
import imaplib
import select
import sys
class mysock():
def __init__(self, name, server, user, passwd, directory):
self.name = name
self.directory = directory
self.M = imaplib.IMAP4(server)
self.M.login(user, passwd)
self.M.select(self.directory)
self.M.send("%s IDLE\r\n"%(self.M._new_tag()))
if not self.M.readline().startswith('+'): # expect continuation response
exit(1)
def fileno(self):
return self.M.socket().fileno()
if __name__ == '__main__':
sockets = [
mysock("Name1", "imap.foo.bar", "user1", "pass1", "folder1"),
mysock("Name1", "imap.foo.bar", "user1", "pass1", "folder2"),
mysock("Name2", "imap.blub.bla", "user2", "pass2", "folder3")
]
readable, _, _ = select.select(sockets, [], [], 1980) # 33 mins timeout
found = False
for sock in readable:
if sock.M.readline().startswith('* BYE '): continue
print "-u basic -o -q -f %s -a %s"%(sock.directory, sock.name)
found = True
break
if not found:
print "-u basic -o"
It would create a connection to every directory I want to watch on every email account I want to synchronize. The select call will expire after 33 minutes as most email servers would drop the connection if nothing happens at around 30 minutes. If something happened within that time though, the script would output the arguments to offlineimap to do a quick check on just that mailbox on that account. If nothing happened, the script would output the arguments to offlineimap to do a full check on all my mailboxes.
while true; do
args=`timeout --signal=KILL 35m python idle.py` || {
echo "idle timed out" >&2;
args="-u basic -o";
}
echo "call offlineimap with: $args" >&2
timeout --signal=KILL 1m offlineimap $args || {
echo "offlineimap timed out" >&2;
continue;
}
notmuch new
done
Every call which interacts with the network is wrapped in a timeout command
to avoid any funny effects. Should the python script timeout, a full
synchronization with offlineimap is triggered. Should offlineimap timeout, an
error message is written to stderr and the script continues. The above
naturally has the disadvantage of not immediately responding to new email which
arrives during the time that idle.py is not running. But as this email will
be fetched once the next message arrives on the same account, there is no much
waiting time and so far, this problem didnt bite me.
Is there a better way to synchronize my email and at a same time make use of IDLE? I'm surprised I didnt find software which would offer this feature.
New bootstrap analysis results
Tue, 28 May 2013 05:55 categories: debianI wrote a small wiki page for botch. It includes links to some hopefully useful resources like my FOSDEM 2013 talk or my master thesis about botch.
The final goal of botch is to generate a build order with which Debian can be bootstrapped from zero to more than 18000 source packages. But such a build order can only be generated once enough source packages (by now the number is around 70) incorporate build profiles which allow to compile them with less build dependencies and thereby break all build dependency cycles. So an intermediary goal of botch is, to find a "good" (i.e. a close to minimal amount) selection of such build dependencies that should be dropped from their source packages. So far, the results of all heuristics we use for this task were just dumped to standard output. Since this textual format was hard to read for a human developer and even worse machine readable, that tool now outputs its results in JSON. This data is then converted by another tool to a more human readable format. One such format is HTML and with the help of javascript for sortable and pageable tables, the data can then be presented without producing too much visual clutter (at least compared to the initial textual format).
Another advantage of HTML is, that the data can now easily be shared with other developers without them having to run botch or install any other program first. So without further ado, please find the result of running our heuristics on Debian Sid as of 2013-01-01 here: http://mister-muffin.de/bootstrap/stats/
Here is a screenshot of what you can expect (you can see part of the table of edges with most cycles through them):
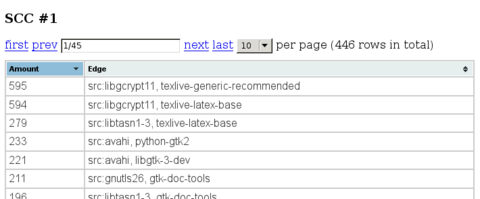
As a developer uses this information to add build profiles to source packages, this HTML page can be regenerated and will show which strongly connected components are now left in the graph and how to best make them acyclic as well.
Besides other improvements I also updated the data I used to generate the graphs from this post. I found this update to be necessary since we found and fixed several implementation bugs since October 2012, so this new plot should be more accurate. Here a graph which shows the amount of vertices in the biggest strongly connected component of Debian Sid by date.

Some datapoints are missing for dates for which important source packages in Sid were not compilable.
botch - the debian bootstrap software has a name
Tue, 16 Apr 2013 07:13 categories: debianAfter nearly one year of development, the "Port bootstrap build-ordering tool" now finally has a name: botch. It stands for Bootstrap/Build Order Tool CHain. Now we dont have to call it "Port bootstrap build-ordering tool" anymore (nobody did that anyways) and also dont have to talk about it by referring to it as "the tools" in email, IRC or in my master thesis which is due in a few weeks. With this, the issue also doesnt block the creation of a Debian package anymore. Since only a handful of people have a clone of it anyway, I also renamed the gitorious git repository url (and updated all links in this blog and left a text file informing about the name change in the old location). The new url is: https://gitorious.org/debian-bootstrap/botch
Further improvements since my last post in January include:
- greatly improved speed of partial order calculation
- calculation of strong edges and strong subgraphs in build graphs and source graphs
- calculation of source graphs from scratch or from build graphs
- calculation of strong bridges and strong articulation points
- calculate betweenness of vertices and edges
- find self-cycles in the source graph
- add webselfcycle code to generate a HTML page of self-cycles
- allow to collapse all strongly connected components of the source graph into a single vertex to make it acyclic
- allow to create a build order for cyclic graphs (by collapsing SCC)
- allow to specify custom installation sets
- add more feedback arc set heuristics (eades, insertion sort, sifting, moving)
- improve the cycle heuristic
In the mean time a paper about the theoretical aspects of this topic which Pietro Abate and I submitted to the CBSE 2013 conference got accepted (hurray!) and I will travel to the conference in Canada in June.
Botch (yeey, I can call it by a name!) is also an integral part of one of the proposals for a Debian Google Summer of Code project this year, mentored by Wookey and co-mentored by myself. Lets hope it gets accepted and produces good results in the end of the summer!
Bootstrappable Debian FOSDEM talk
Fri, 01 Feb 2013 11:05 categories: debianI will give a talk about the current status of automating Debian bootstrapping at FOSDEM 2013. There will also be a live demo of the developed toolchain. The talk will start 16:30 on Saturday, 2 February 2013 in room H.1302 as part of the Cross distro devroom track and will be half an hour long. Directly after my talk, at 17:00, Wookey will give his about bootstrapping Debian/Ubuntu for arm64 in the same location.
The current version of the slides can be downloaded here. The latex beamer source is available in the git repository of the debian bootstrap project.
If you can't make it to FOSDEM, then my last post about the topic gives away most of the things I will be talking about.
Bootstrappable Debian - New Milestone
Fri, 25 Jan 2013 11:42 categories: debianThis post is about the port bootstrap build ordering tool (naming suggestions welcome) which was started as a Debian Google Summer of Code project in 2012 and continued to be developed afterwards. Sources are available through gitorious.
In the end of November 2012, I managed to put down an approximation algorithm to the feedback arc set problem which allowed to break the dependency graph into a directed acyclic graph with only few removed build dependencies. I wrote about this effort on our mailinglist but didnt mention it here because it was still too much of a proof-of-concept. Later, in January 2013, I mentioned the result of this algorithm in an email wookey and me wrote to debian-devel mailinglist.
Many things happened since November 2012:
Processing pipeline instead of monolithic tools
The tools I developed so far tried to accomplish everything by themselves, reusing functionality implemented in a central library. Therefor, if one wanted to try out even trivial new things, it mostly meant to hack some OCaml code. Pietro Abate suggested to instead develop smaller tools which could work independently of each other, would only execute one algorithm each and could easily be connected together in different ways to achieve different effects.
This switch is now done and all functionality from the old tools is moved into a new toolset. The exchange format between the tools is either plain text files in deb822 control format (Packages/Sources files) or a dependency graph. The dependency graph is currently marshalled by OCaml but future versions should work with just passing a GraphML (an XML graph format) representation around.
This new way of doing things seems close to the UNIX philosophy (each program
does one thing well, data is stored as text, every program is a filter). For
example the deb822 control output can easily be manipulated using
grep-dctrl(1) and there exist many tools which can read, analyze and
manipulate GraphML. It is a big improvement over the old, monolithic tools
which did not allow to manipulate any intermediate result by external, existing
tools. Currently, a shell script (native.sh) will execute all tools in a
meaningful order, connecting them together correctly. The same tools will be
used for a future cross.sh but they will be connected differently.
I wrote about a first proposal of what the individual tools should do and how they should be connected in this email from which I also linked a confusing overview of the pipeline. This overview has recently been improved to be even more confusing and the current version of the lower half (the native part) now looks like this:
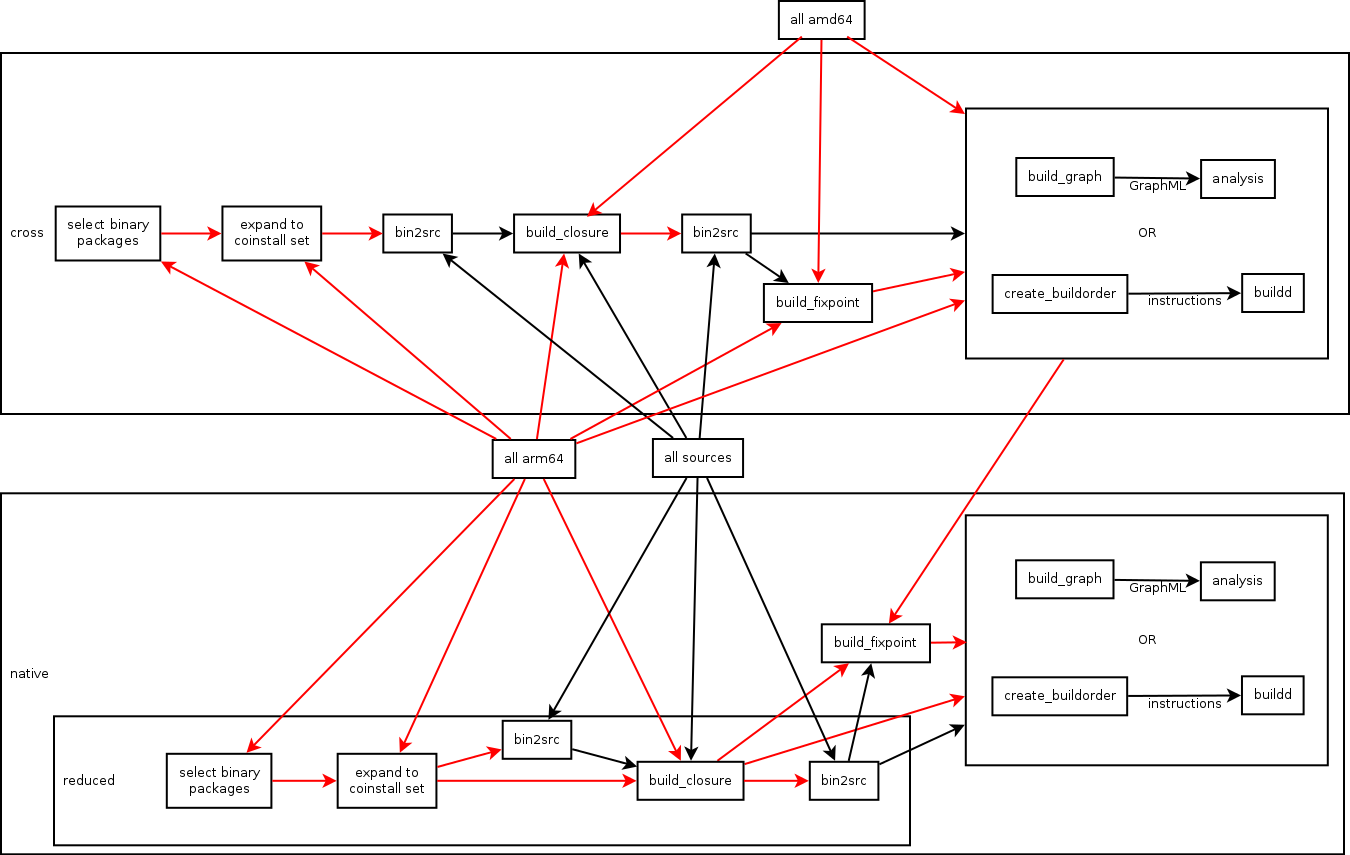{kind=link}
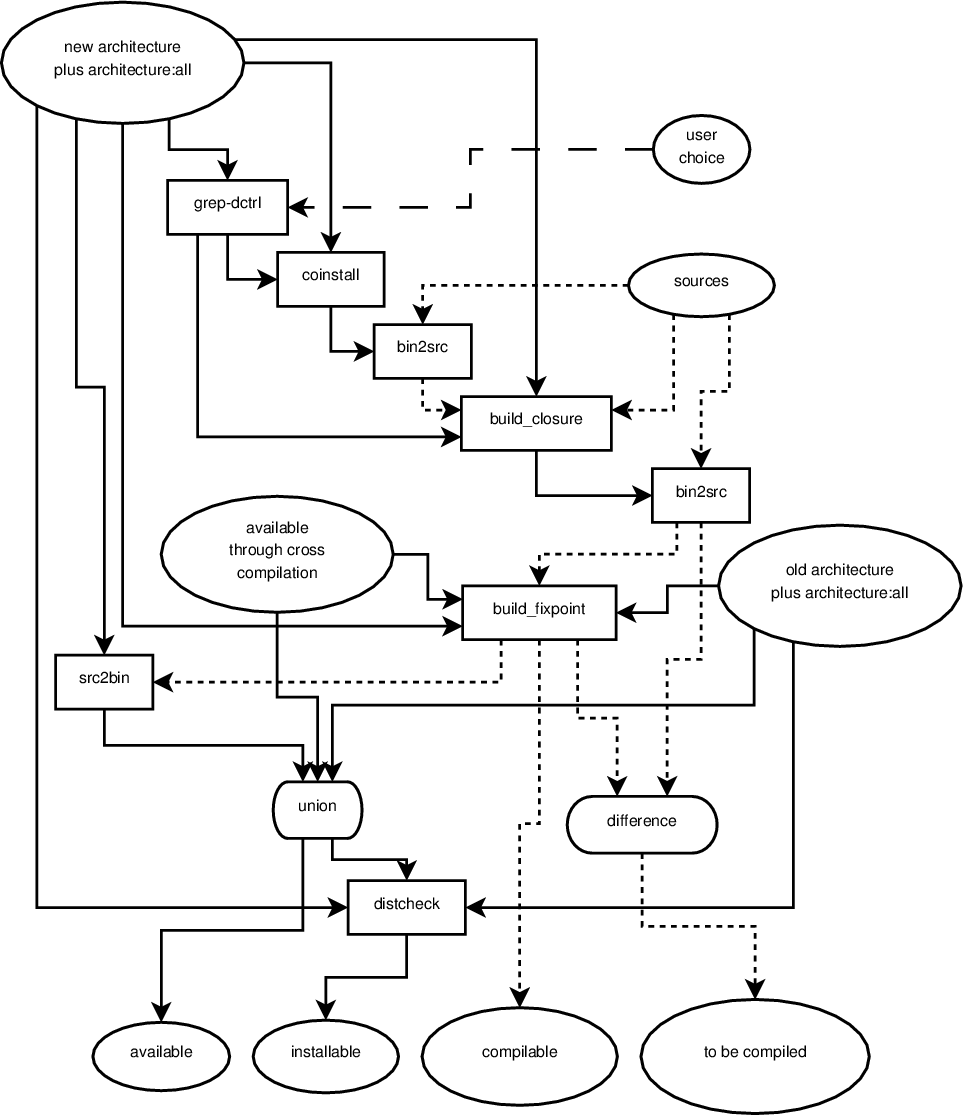
Solid arrows represent a flow of binary packages, dottend arrows represent a
flow of source packages, ovals represent a set of packages, boxes with rounded
corners represent set operations, rectangular boxes represent filters. There is
only one input to a filter, which is the arrow connected to the top of the box.
Outgoing arrows from the bottom represent the filtered input. Ingoing arrows
to either side are arguments to the filter and control how the filter behaves
depending on the algorithm. I will explain this better once the pipeline proved
to be less in flux. The pipeline is currently executed like this by
native.sh.
Two new ways to break dependency cycles have been discovered
So far, we knew of three ways to formally break dependency cycles:
- remove build dependencies through build profiles
- find out that the build dependency is only used to build arch:all packages and therefor put it into Build-Depends-Indep
- cross compile some source packages
Two new methods can be added to the above:
- if a dependency relationship is not strong (pdf), then a different installationset can be chosen
- if a depended upon package is Multi-Arch:foreign then a binary package of an existing architecture might be able to satisfy the dependency.
Dependency graph definition changed
Back in September when I was visiting irill, Pietro found a flaw in how the dependency graph used to be generated. He supplied a new definition of the dependency graph which does away with the problem he found. After fixing some small issues with his code, I changed all the existing algorithms to use the new graph definition. The old graph is as of today removed from the repository. Thanks to Pietro for supplying the new graph definition - I must still admit that my OCaml foo is not strong enough to have come up with his code.
Added complexity for profile built source packages
As mentioned in the introduction, wookey and me addressed the debian-devel list with a proposal on necessary changes for an automated bootstrapping of Debian. During the discussiong, two important things came up which are to be considered by the dependency graph algorithms:
- profile built source packages may not create all binary packages
- profile built source packages may need additional build dependencies
Both things make it necessary to alter the dependency graph during the generation of a feedback arc set and feedback vertex set beyond the simple removal of edges. Luckily, the developed approximation algorithms can be extended to support such changes in the graph.
Different feedback arc set algorithms
The initially developed feedback arc set algorithm is well suited to discover build dependency edges which should be dropped. It performs far worse when creating the final build order because it only considers edges by itself and not how many edges of a source package can be dropped by profile building it.
The adjusted algorithm for generating a build order is more of a feedback vertex set algorithm because instead of greedily finding the edge with most cycles through it, it greedily finds the source package which would break most cycles if it was profile built.
Generating a build order with less profile built source packages
After implementing all the features above I now feel more confident to publish the current status of the tools to a wider audience.
The following test shows a run of the aforementioned ./native.sh shell
script. Its final output is a list of source packages which have to be profile
built and a build order. Using the resulting build order, starting from a
minimal build system (essential:yes, build-essential and debhelper), all source
packages will be compiled which are needed to compile all binary packages in
the system. The result will therefor be a list of source and binary packages
which fulfill the following property:
- all binary packages can be built from the available source packages
- all source packages can be built with the available binary packages
I called this a "reduceded distribution" in earlier posts. The interesting property of this specific selection is, that it contains the biggest problem set of Debian when bootstrapping it: a 900 to 1000 nodes big strongly connected component. Here is a visualization of the problem:
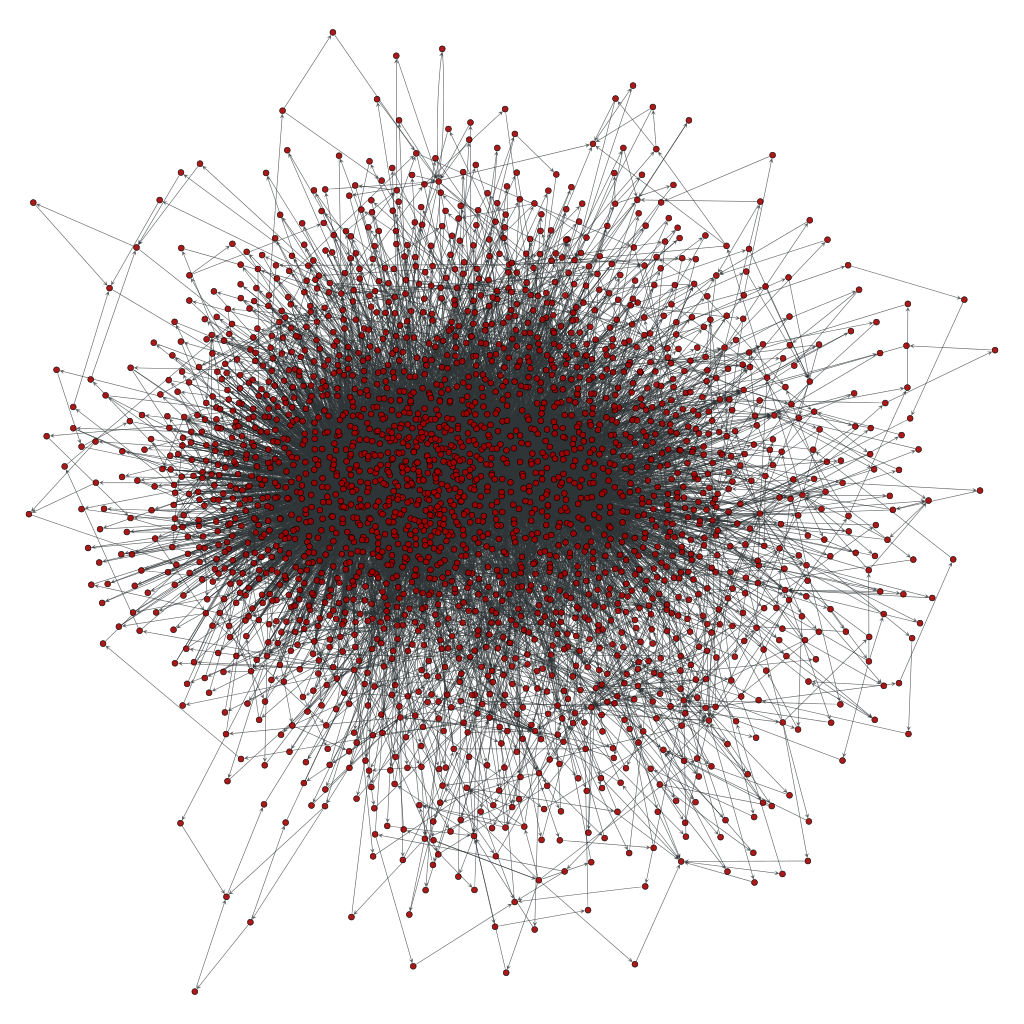
Source packages do not yet come with build profiles and the cross build situation can not yet be analyzed, so the following assumptions were made:
- the minimal build system can be cross compiled from nothing
- the reduced build dependencies harvested from Gentoo and supplied by Daniel Schepler, Patrick McDermott, Thorsten Glaser and Wookey are correct
- the current list of weak build dependencies can be dropped from any source package
- even when profile built, all source packages build all binary packages
- the 14 forcefully broken build dependencies do not significantly change the output in real life
The last point is about 14 build dependencies which were decided to be broken
by the feedback arc set algorithm but for which other data sources did not
indicate that they are actually breakable. Those 14 are dynamically generated
by native.sh.
If above assumptions should not be too far from the actual situation, then not
more than 73 source packages have to be modified to bootstrap a reduced
distribution. This reduced distribution even includes dependency-wise "big"
packages like webkit, metacity, iceweasel, network-manager, tracker,
gnome-panel, evolution-data-server, kde-runtime, libav and nautilus. By
changing one line in native.sh one could easily develop a build order which
generates gnome-desktop or really any given (meta-)package selection.
All of native.sh takes only 80 seconds to execute on my system (Core i5, 2.5
GHz, singlethreaded). Here is the final build order which creates 2044 binary
packages from 613 source packages.
- nspr, libio-pty-perl, libmcrypt, unzip, libdbi-perl, cdparanoia, libelf, c-ares, liblocale-gettext-perl, libibverbs, numactl, ilmbase, tbb, check, libogg, libatomic-ops, libnl($), orc($), libaio, tcl8.4, kmod, libgsm, lame, opencore-amr, tcl8.5, exuberant-ctags, mhash, libtext-iconv-perl, libutempter, pciutils, gperf, hspell, recode, tcp-wrappers, fdupes, chrpath, libbsd, zip, procps, wireless-tools, cpufrequtils, ed, libjpeg8, hesiod, pax, less, dietlibc, netkit-telnet, psmisc, docbook-to-man, libhtml-parser-perl, libonig, opensp($), libterm-size-perl, linux86, libxmltok, db-defaults, java-common, sharutils, libgpg-error, hardening-wrapper, cvsps, p11-kit, libyaml, diffstat, m4
- openexr, enca, help2man, speex, libvorbis, libid3tag, patch, openjade1.3, openjade, expat, fakeroot, libgcrypt11($), ustr, sysvinit, netcat, libirman, html2text, libmad, pth, clucene-core, libdaemon($), texinfo, popt, net-tools, tar, libsigsegv, gmp, patchutils($), dirac, cunit, bridge-utils, expect, libgc, nettle, elfutils, jade, bison
- sed, indent, findutils, fastjar, cpio, chicken, bzip2, aspell, realpath, dctrl-tools, rsync, ctdb, pkg-config($), libarchive, gpgme1.0, exempi, pump, re2c, klibc, gzip, gawk, flex-old, original-awk, mawk, libtasn1-3($), flex($), libtool
- libcap2, mksh, readline6, libcdio, libpipeline, libcroco, schroedinger, desktop-file-utils, eina, fribidi, libusb, binfmt-support, silgraphite2.0, atk1.0($), perl, gnutls26($), netcat-openbsd, ossp-uuid, gsl, libnfnetlink, sg3-utils, jbigkit, lua5.1, unixodbc, sqlite, wayland, radvd, open-iscsi, libpcap, linux-atm, gdbm, id3lib3.8.3, vo-aacenc, vo-amrwbenc, fam, faad2, hunspell, dpkg, tslib, libart-lgpl, libidl, dh-exec, giflib, openslp-dfsg, ppl($), xutils-dev, blcr, bc, time, libdatrie, libpthread-stubs, guile-1.8, libev, attr, libsigc++-2.0, pixman, libpng, libssh2, sqlite3, acpica-unix, acl, a52dec
- json-c, cloog-ppl, libverto, glibmm2.4, rtmpdump, libdbd-sqlite3-perl, nss, freetds, slang2, libpciaccess, iptables, e2fsprogs, libnetfilter-conntrack, bash, libthai, python2.6($), libice($), libpaper, libfontenc($), libxau, libxdmcp($), openldap($), cyrus-sasl2($), openssl, python2.7($)
- psutils, libevent, stunnel4, libnet-ssleay-perl, libffi, readline5, file, libvoikko, gamin, libieee1284, build-essential, libcap-ng($), lcms($), keyutils, libxml2, libxml++2.6, gcc-4.6($), binutils, dbus($), libsm($), libxslt, doxygen($)
- liblqr, rarian, xmlto, policykit-1($), libxml-parser-perl, tdb, devscripts, eet, libasyncns, libusbx, icu, linux, libmng, shadow, xmlstarlet, tidy, gavl, flac, dbus-glib($), libxcb, apr, krb5, alsa-lib
- usbutils, enchant, neon27, uw-imap, libsndfile, yasm, xcb-util, gconf($), shared-mime-info($), audiofile, ijs($), jbig2dec, libx11($)
- esound, freetype, libxkbfile, xvidcore, xcb-util-image, udev($), libxfixes, libxext($), libxt, libxrender
- tk8.4, startup-notification, libatasmart, fontconfig, libxp, libdmx, libvdpau, libdrm, libxres, directfb, libxv, libxxf86dga, libxxf86vm, pcsc-lite, libxss, libxcomposite, libxcursor, libxdamage, libxi($), libxinerama, libxrandr, libxmu($), libxpm, libxfont($)
- xfonts-utils, libxvmc, xauth, libxtst($), libxaw($)
- pmake, corosync, x11-xserver-utils, x11-xkb-utils, coreutils, xft, nas, cairo
- libedit, cairomm, tk8.5, openais, pango1.0($)
- ocaml, blt, ruby1.8, firebird2.5, heimdal, lvm2($)
- cvs($), python-stdlib-extensions, parted, llvm-2.9, ruby1.9.1, findlib, qt4-x11($)
- xen, mesa, audit($), avahi($)
- x11-utils, xorg-server, freeglut, libva
- jasper, tiff3, python3.2($)
- openjpeg, qt-assistant-compat, v4l-utils, qca2, jinja2, markupsafe, lcms2, sip4, imlib2, netpbm-free, cracklib2, cups($), postgresql-9.1
- py3cairo, pycairo, pam, libgnomecups, gobject-introspection($)
- gdk-pixbuf, libgnomeprint, gnome-menus, gsettings-desktop-schemas, pangomm, consolekit, vala-0.16($), colord($), atkmm1.6
- libgee, gtk+3.0($), gtk+2.0($)
- gtkmm2.4, poppler($), openssh, libglade2, libiodbc2, gcr($), libwmf, systemd($), gcj-4.7, java-atk-wrapper($)
- torque, ecj($), vala-0.14, gnome-keyring($), gcc-defaults, gnome-vfs($)
- libidn, libgnome-keyring($), openmpi
- mpi-defaults, dnsmasq, wget, lynx-cur, ghostscript, curl
- fftw3, gnupg, libquvi, xmlrpc-c, raptor, liboauth, groff, fftw, boost1.49, apt
- boost-defaults, libsamplerate, cmake, python-apt
- qjson, qtzeitgeist, libssh, qimageblitz, pkg-kde-tools, libical, dwarves-dfsg, automoc, attica, yajl, source-highlight, pygobject, pygobject-2, mysql-5.5($)
- libdbd-mysql-perl, polkit-qt-1, libdbusmenu-qt, raptor2, dbus-python, apr-util
- rasqal, serf, subversion($), apache2
- git, redland
- xz-utils, util-linux, rpm, man-db, make-dfsg, libvisual, cryptsetup, libgd2, gstreamer0.10
- mscgen, texlive-bin
- dvipng, luatex
- libconfig, transfig, augeas, blas, libcaca, autogen, libdbi, linuxdoc-tools, gdb, gpm
- ncurses, python-numpy($), rrdtool, w3m, iproute, gcc-4.7, libtheora($), gcc-4.4
- libraw1394, base-passwd, lm-sensors, netcf, eglibc, gst-plugins-base0.10
- libiec61883, qtwebkit, libvirt, libdc1394-22, net-snmp, jack-audio-connection-kit($), bluez
- redhat-cluster, gvfs($), pulseaudio($)
- phonon, libsdl1.2, openjdk-6($)
- phonon-backend-gstreamer($), gettext, libbluray, db, swi-prolog, qdbm, swig2.0($)
- highlight, libselinux, talloc, libhdate, libftdi, libplist, python-qt4, libprelude, libsemanage, php5
- samba, usbmuxd, libvpx, lirc, bsdmainutils, libiptcdata, libgtop2, libgsf, telepathy-glib, libwnck3, libnotify, libunique3, gnome-desktop3, gmime, glib2.0, json-glib, libgnomecanvas, libcanberra, orbit2, udisks, d-conf, libgusb
- libgnomeprintui, libimobiledevice, nautilus($), libbonobo, librsvg
- evas, wxwidgets2.8, upower, gnome-disk-utility, libgnome
- ecore, libbonoboui
- libgnomeui
- graphviz
- exiv2, libexif, lapack, soprano, libnl3, dbus-c++
- atlas, libffado, graphicsmagick, libgphoto2, network-manager
- pygtk, jackd2, sane-backends, djvulibre
- libav($), gpac($), ntrack, python-imaging, imagemagick, dia
- x264($), matplotlib, iceweasel
- strigi, opencv, libproxy($), ffms2
- kde4libs, frei0r, glib-networking
- kde-baseapps, kate, libsoup2.4
- geoclue, kde-runtime, totem-pl-parser, libgweather, librest, libgdata
- webkit
- zenity, gnome-online-accounts
- metacity, evolution-data-server
- gnome-panel
- tracker
The final recompilation of profile built source packages is omitted. Source packages marked with a ($) are selected to be profile built. All source packages listed in the same line can be built in parallel as they do not depend upon each other.
This order looks convincing as it first compiles a multitude of source packages which have no or only few build dependencies lacking. Later steps allow fewer source packages to be compiled in parallel. The amount of needed build dependencies is highest in the source packages that are built last.